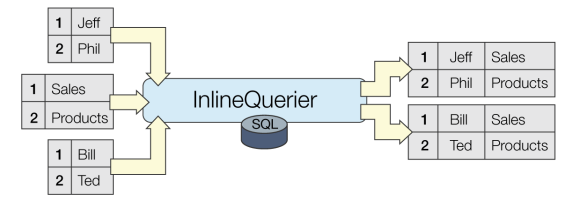
InlineQuerier
Any number of tables can be created, and each will be assigned an input port. Any features can be routed to that input port as long as they supply values for each column defined for the table. Similarly, any number of queries can be specified, and each is assigned an output port through which the features which result from that query will be routed. The queries can involve any and all tables and columns defined in the input. In particular, multi-way joins can be executed, advanced SQL operations involving nested Select statements and advanced predicates can be used, and the input tables can be used by multiple queries.
This transformer is particularly useful to SQL-enable input streams of features coming from sources that have no SQL ability, as well as to perform multi-way joins across streams.
An InlineQuerier transformer added into a workspace initially has no input or output ports. You must configure it to define at least one table and at least one associated query. These table definitions and associated queries then become the transformer’s respective input and output ports.
The InlineQuerier uses a SQLite database to store the tables and then execute the queries. See http://www.sqlite.org/lang_select.html for a detailed reference on the SQL Select statement syntax that is supported.
Parameters
Inputs
The InlineQuerier requires definition of one or more Tables, which will become input ports to the transformer. The Import… button provides a quick way to populate the input table definitions from the source feature types in the workspace. To add an input port, you must define a table name and some columns against which queries may be performed.
Note: For performance reasons, you should define as few columns as possible.
At runtime, the transformer will build an index for each of the columns before any of the queries are processed. In addition to the columns defined, a special fme_feature_content column is implicitly defined on every table, and at runtime this column can be considered to contain the entire contents of the FME feature that entered through the table’s port. Because of this, only attributes that will be used in filtering or joining should be defined for the table – any additional attributes (as well as feature geometry) can be put onto the resulting output features by selecting the fme_feature_content column.
Outputs
Each output port is assigned an SQL query. A helpful editor is used to construct the queries, and provides convenient drag and drop access to tables, columns, and published and private parameters which can be used within the query. The Generate button will create one output port with a default Select * query for each input table.
At the end of translation, each connected port's queries will be executed against the InlineQuerier's temporary database. A feature is emitted from the output port for each row which results from executing the SQL query.
If the result of a query includes the fme_feature_content attribute (either explicitly or through the use of a SELECT *), then the content of the original feature will be included on the output feature.
In the event where the query joins multiple tables with multiple values of fme_feature_content, the attributes of the resulting features will be merged in the order in which the fme_feature_content values are encountered in the query. If the original features had attributes with the same names, then the first fme_feature_content found in the resulting row will have its feature attributes on the output feature, and subsequent fme_feature_content will have their duplicate feature attributes ignored during the merging. (If this is not desired, you could use an AttributeRenamer prior to the InlineQuerier to ensure unique attribute names in the input streams.)
Additionally, the resulting merged feature will, by default, have the geometry from the first source feature encountered. You may define the type of geometry for the query to "aggregate of all features"; in this case, the resulting merged feature will contain an aggregate geometry of all of the input features, in the order in which their respective fme_feature_content values were encountered.
Coordinate System of Output Features
The coordinate system on the output feature will be:
- unset if no fme_feature_content was selected;
- set to that of the first feature if you are selecting feature content with "First Feature";
- set to the common coordinate system of all "content" features, if "Aggregate" mode is in effect and all input features have the same coordinate system.
Otherwise it will be left unset.
Note: A note on table contents: The tables defined for the input ports require the attributes of the source features against which the queries will be performed. They do not have to – and should not – contain additional attributes. In the normal case, a SELECT * type of query will be performed, which will bring in all of the attributes and source geometry from the original feature because it will include the special fme_feature_content column.
Note: A note on features routed to input ports: Features routed to input ports should have attributes on them which match the schema defined for the input port table. If they do not, null values will be inserted in place of missing attributes for the columns defined for the input table. An upstream AttributeRenamer or NullAttributeMapper can be used to ensure that attribute values are present for defined columns.
Usage Notes
Relationship to FeatureMerger
The InlineQuerier is the powerful cousin of the FeatureMerger. Whereas the FeatureMerger joins two datasets and uses a simple, single attribute key to match features, the InlineQuerier allows any number of input datasets to be merged, using the full power of SQL across any number of tables and columns. Furthermore, the InlineQuerier allows its input data to be reused multiple times in a single transformer, whereas if multiple joins are to be done with a FeatureMerger, multiple FeatureMergers must be employed and copies of the features sent to each. On the other hand, there is some overhead for the InlineQuerier to load the underlying SQLite database. Using a single InlineQuerier instead of several FeatureMergers also simplifies the workspace.
Unless only a single FeatureMerger is needed in a workflow, the InlineQuerier may be a better choice. Older workspaces with multiple cascading FeatureMergers may experience a performance improvement by replacing the FeatureMergers with a single properly configured InlineQuerier.
Relationship to SQLCreator/SQLExecutor
If all the data to be queried already exists in a SQL-capable data source, it is always more efficient to use the SQLCreator or SQLExecutor, because this allows the queries and filtering of the data to be executed directly by the database before it enters the FME environment.
Relationship to Joiner
The Joiner is very useful and efficient when there exists a one-to-one or one-to-many relationship between data flowing through FME and data held within a database. If it can be used, the Joiner can be more efficient than using either the InlineQuerier or SQLCreator/SQLExecutor, provided that the Joiner key fields have indexes in the source database. Joiner allows simple join relationships based on multiple attribute keys and requires no knowledge of SQL – this is often very effective for simple lookup tables. The InlineQuerier is useful in cases where data sources have no SQL ability, or for more complex queries. The InlineQuerier allows you to ask more sophisticated questions about the data than the Joiner.
Example
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Transformer Categories
Search FME Knowledge Center
Search for samples and information about this transformer on the FME Knowledge Center.