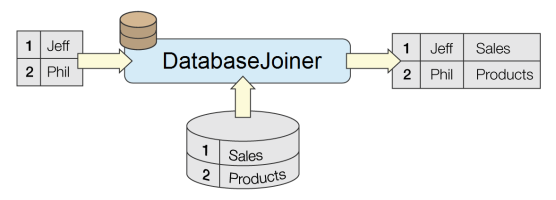
DatabaseJoiner: Joins attributes from an external table to incoming features as they are being processed through a translation.
The DatabaseJoiner queries an external table to retrieve attributes associated with a feature. One or more feature attributes are joined to one or more columns in a table in the database, and the values from the matching table row(s) are added as feature attributes.
The _matched_records attribute specifies how many records in the database the feature matched to.
Output Ports
Features that successfully matched.
Features that had no matches.
If Cardinality is set to Must Match Exactly One or Must Match Zero or One, then features that do not meet the criteria are rejected.
Parameters
The DatabaseJoiner is a very powerful transformer with many performance-related settings.
Reader
Select the Reader format and dataset where the table resides, including any format-specific parameters.
Join
Specify the table to join. Click the Browse button to select the table from a list. Note that you can only select this after you have completely specified the reader format, dataset, and format-specific parameters.
Select the attribute(s) from the incoming feature and their corresponding table field(s) that will be used to find matches. Matches are made when the values of all the attributes equal the values of their corresponding table fields.
There is one row for each attribute and column pair in the table entry widget. You can add more pairs by clicking the plus (+) button located to the right of the table. Similarly, you can remove pairs by pressing the minus (-) button. A minimum of one pair must be specified for the join to work.
Select attributes from a drop-down list in the Feature Attributes column. (You can type directly in the corresponding table fields or select from a list by clicking the Browse button.) For the Browse button to list available table fields, all the information needed to read from the table needs to be specified.
Specify a list of fields from the matching table rows to join onto the incoming feature.
To select the fields from a list, click the Browse button. A dialog showing the list of possible fields will appear. Place a check next to each field you wish to add, and click OK.
If no fields are specified, all the fields from the matching rows will be added.
Indicate the type of relationship between the database rows and each feature. This will describe how many rows will match to each feature and what action the DatabaseJoiner will take if the expected number is not found.
| Relationship Type | Description |
|---|---|
| Match All (1:M) | A feature can match to any number of records, all of which will be joined based on the value of the Multiple Matches parameter. |
| Match First (1:0..1+) | A feature can match to any number of records, or none at all, but only the first record found will be joined. |
| Must Match Exactly One (1:1) | Each feature MUST match to one record only. Zero matches or more than one match will cause feature rejection. |
| Must Match Zero or One (1:0..1) | Each feature MUST match to a single record or none at all. More than one match will cause feature rejection. |
Note: The Must Match rules are very strict. When in doubt, use Match First or Match All.
Specify how results of multiple matches will be given.
Create a feature for each match: Each row matched is added to a copy of the incoming feature. In this scenario, for each feature in, there will be matched features out. If there are no matches, the feature exits the Unjoined output port.
Add fields on a list attribute: Each row matched is added to a list attribute on the feature. If there are no matches, the feature exits the Unjoined output port.
The name of the list attribute to append multiple matches.
Note: List attributes are not accessible from the output schema in Workbench unless they are first processed using a transformer that operates on them, such as ListExploder or ListConcatenator. All list attribute transformers are displayed in the Contents pane of the Transformer Help under Lists. Alternatively, AttributeExposer can be used.
Merge Attributes
If Merge Joined is chosen, attributes from the feature and table will be merged, and in case of conflicts the value specified in the Conflict Resolution parameter will be used. If Prefix Joined is chosen, then all incoming attributes will be presented with a prefix set in the Prefix parameter.
This parameter is enabled when Accumulation Mode is set to Merge Joined. Use Original and Use Joined will give priority to original and incoming attributes respectively in case of attribute conflicts.
The specified value is used as a prefix for incoming attributes when Accumulation Mode is Prefix Joined.
Optimize
Normally the cache is filled with records as they are matched in the database. However, for formats that support SQL, the cache can be preloaded (that is, filled with a specific set of data before matching takes place) by issuing a prefetch query. This prefetch query can select an entire table or a selected part of a table which is most likely to be matched by the feature attributes.
Note: Unless the prefetch query is exhaustive, cache size limits apply. See Prefetch Exhaustive to learn what constitutes an exhaustive prefetch query
A prefetch query which is known to retrieve all possible matches is called an exhaustive query. When a match cannot be found within the cached results of an exhaustive query, it is assumed that no match exists in the database; thus the database will not be further consulted.
If Prefetch Exhaustive is set to Yes, this indicates whether a prefetch is exhaustive. Even when it is set to No, however, any prefetch query is assumed to be exhaustive when it does not contain a WHERE clause, and is of the form:
SELECT * from TableName
Note: When FME considers a prefetch query to be exhaustive, the cache size limit will be ignored. This is because the cache must contain all results from the query.
For example, a number of FME features of type "roads" require a database match. The database table (myrecords) has a field (record_type) with a number of values; roads, highways, avenues, streets. The FME features will only ever be matched to where record_type=roads so the overall join process would be much more efficient if the following prefetch was issued:
SELECT * from myrecords where record_type = 'roads'
Specify the number of rows to cache locally if you do not want to accept the default of 5000. You can optionally specify an SQL query to preload the cache. Note that cache size is ignored if the prefech query is exhaustive.
Engaging trimming of key fields may significantly reduce performance and should only be done if key column values in the database are known to contain trailing spaces.
It has no effect if an exhaustive prefetch query is used (see above for an explanation of Prefetch Exhaustive).
Note: This parameter is included for backwards compatibility and most users will have no need to use it. The parameter can only be accessed using the pane of the Workbench.
Tip:
Usage Notes
Relationship to FeatureMerger
The FeatureMerger joins two datasets being read in a workspace. FeatureMerger is also able to perform certain geometric operations on incoming features using its Merge Type parameter. FeatureMerger performs all joins in memory, so it can be faster than the DatabaseJoiner if you have more than one relationship on the same data. DatabaseJoiner joins are performed by the database using SQL. The article FME2011 Use Case: Joiner vs FeatureMerger contains a more detailed comparison of these transformers.
Relationship to InlineQuerier/SQLCreator/SQLExecutor
The DatabaseJoiner is very useful and efficient when there exists a one-to-one or one-to-many relationship between data flowing through FME and data held within a database. If it can be used, the DatabaseJoiner can be more efficient than using either the InlineQuerier or SQLCreator/SQLExecutor, provided that the DatabaseJoiner key fields have indexes in the source database. DatabaseJoiner allows simple join relationships based on multiple attribute keys and requires no knowledge of SQL – this is often very effective for simple lookup tables. SQLCreator/SQLExecutor allow more complex joins and these are executed by the source database.
The InlineQuerier is useful in cases where data sources have no SQL ability, or for more complex queries. The InlineQuerier allows you to ask more sophisticated questions about the data than the DatabaseJoiner.
Example
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Transformer Categories
Search FME Knowledge Center
Search for samples and information about this transformer on the FME Knowledge Center.