Note: This is an extra-cost transformer, available from Safe Software. Please contact sales@safe.com or call 604-501-9985.
MRF Geosystems Corporation (www.mrf.com) has produced cleaning software and made it available to FME users to apply to data as it is transformed between arbitrary input and output formats.1Portions of this work are the intellectual property of the MRF Geosystems Corporation and are used under license. Copyright © 2006 MRF Geosystems Corporation. All rights reserved.
The MRFCleaner repairs geometry, particularly during data migration from CAD to GIS, and is built upon the MRFCleanFactory, which is an integration of MRF’s cleaning technology into FME.
The MRFCleaner fixes geometric problems in input data such as line overshoots and undershoots within the user-specified tolerance. It is useful for multi-layer and multi-tolerance three-dimensional data cleaning. Typical applications include the correction of utility maps, parcel maps, topographic maps and resource maps as data is migrated from one system to another.
The MRFCleaner includes the following functionality:
- fuzzy tolerance
- extending lines
- weeding lines
- joining lines
- processing short elements
- removing gaps
- removing duplicates
- removing dangles
- performing conflation
The number of layers used in cleaning the data is determined by the number of different cleaning tolerance values of input features. Features that have the same cleaning tolerances are processed as being on the same layer. This allows feature data from a high-quality data source to be assigned a low cleaning tolerance and integrated with data from a lower-quality data source which would be given a larger cleaning tolerance.
Geometries such as path, polygon, donut, ellipse, elliptical arc, multi-area, multi-curve, text, and multi-text are converted to basic geometries such as point, line, path, arc or multi-point prior to the cleaning process. The cleaner understands and works with circular arcs. Input features with invalid geometries are ignored and deleted.
Usage Tips
You can also use one more of the following transformers to perform singular MRFCleaner operations. These transformer parameters are all available as part of this MRF2DCleaner transformer, but you may wish to use separate transformers so that the operations are more easily visible in your workflow.
Output Ports
Each feature that is output through the Cleaned port has a new attribute mrf_clean_status added to specify whether the feature is modified, created, or will remain unchanged in the cleaning process. The possible values of this attribute are "Modified", "Created" and "Original".
Features can also be output through the Flagged port if any of the Remove Dangles, Remove Short Geometries and Compute True Intersections is set to Flag. Each of these features has a new attribute mrf_clean_flag added to specify whether this feature is flagged as being shorter than the cleaning tolerance value ("short"), a dangling geometry ("dangle") or an intersection point ("intersection").
Parameters
Transformer
The default behavior is to use the entire set of input features as the group. This option allows you to select attributes that define which groups to form—each set of features that have the same value for all of these attributes will be processed as an independent group.
Note: How parallel processing works with FME: see About Parallel Processing for detailed information.
This parameter determines whether or not the transformer should perform the work across parallel processes. If it is enabled, a process will be launched for each group specified by the Group By parameter.
Parallel Processing Levels
For example, on a quad-core machine, minimal parallelism will result in two simultaneous FME processes. Extreme parallelism on an 8-core machine would result in 16 simultaneous processes.
You can experiment with this feature and view the information in the Windows Task Manager and the Workbench Log window.
No: This is the default behavior. Processing will only occur in this transformer once all input is present.
By Group: This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger batch processing on the currently accumulating group. This will improve overall speed if groups are large/complex, but could cause undesired behavior if input groups are not truly ordered.
Using Ordered input can provide performance gains in some scenarios, however, it is not always preferable, or even possible. Consider the following when using it, with both one- and two-input transformers.
Single Datasets/Feature Types: Are generally the optimal candidates for Ordered processing. If you know that the dataset is correctly ordered by the Group By attribute, using Input is Ordered By can improve performance, depending on the size and complexity of the data.
If the input is coming from a database, using ORDER BY in a SQL statement to have the database pre-order the data can be an extremely effective way to improve performance. Consider using a Database Readers with a SQL statement, or the SQLCreator transformer.
Multiple Datasets/Feature Types: Since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group, using Ordering with multiple feature types is more complicated than processing a single feature type.
Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
One approach is to send all features through a Sorter, sorting on the expected Group By attribute. The Sorter is a feature-holding transformer, collecting all input features, performing the sort, and then releasing them all. They can then be sent through an appropriate filter (TestFilter, AttributeFilter, GeometryFilter, or others), which are not feature-holding, and will release the features one at a time to the transformer using Input is Ordered By, now in the expected order.
The processing overhead of sorting and filtering may negate the performance gains you will get from using Input is Ordered By. In this case, using Group By without using Input is Ordered By may be the equivalent and simpler approach.
In all cases when using Input is Ordered By, if you are not sure that the incoming features are properly ordered, they should be sorted (if a single feature type), or sorted and then filtered (for more than one feature or geometry type).
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains.
Parameters
This is used as the default cleaning tolerance unless the Feature Tolerance Attribute is specified and valid. The minimum cleaning tolerance allowed is 0.0.
The number of layers used in cleaning the data is determined by the number of different cleaning tolerance values of input features. Features that have the same cleaning tolerances are processed as being on the same layer.
If set to Yes, intersections between all input features are computed, breaking arcs and lines wherever an intersection occurs.
If set to Flag, the intersection point will be output through the Flagged port, with an mrf_clean_flag attribute set to "intersection".
If Yes, a fuzzy intersection is created from geometries which are within one of the cleaning tolerance distances, but do not actually touch or cross.
If set to Yes, arcs and lines that are within the specified cleaning tolerance are extended – while maintaining line-work direction. No intersections are created while doing this. This option does not process overshoots; a combination of Compute Intersections and Remove Short Geometries can serve this purpose.
If set to Yes, a number of vertices of lines are removed. The number of vertices removed is controlled by a weeding tolerance of the value of (Filter Factor * value of Cleaning Tolerance) or (Filter Factor * value of Feature Tolerance Attribute). The latter is always used when it is valid and the Feature Tolerance Attribute is specified. The larger the value of weeding tolerance, the more vertices will be removed.
If set to Yes, then features that have at least one free end point and have lengths smaller than (Dangle Factor * value of Cleaning Tolerance) or (Dangle Factor * value of Feature Tolerance Attribute) are removed.
If set to Remove Short and Flag Long, then features that have at least one free end point will either be removed as above, or its end point will be output through the Flagged port, with an mrf_clean_flag attribute set to "dangle".
The default value of Dangle Factor is 1.0 and the minimum is 0.0.
This parameter is used with Remove Dangles to determine if a dangling feature is too short.
The default value is 1.0 and the minimum value is 0.0.
This parameter is used with Generalize Lines to determine a weeding tolerance.
The default value is 1.0 and the minimum value is 0.0.
Geometries
If set to Yes, features that have lengths smaller than the specified cleaning tolerances are deleted.
If set to Flag, a point on the feature will be output through the Flagged port, with an mrf_clean_flag attribute set to "short".
If set to Yes, duplicated features are deleted. Features are considered to be duplicates if their geometries are within the cleaning tolerance and only features with a smaller cleaning tolerance will remain after cleaning.
If set to Yes, then singly-connected features are joined to form longer ones. A pair of linear features becomes a candidate for joining only when the two are singly connected at a given node or end point.
If set to Yes, then the geometry of a feature can be changed to match that of another, if the two are approximately the same to begin with.
If set to Yes, then area features such as polygons or donuts will be cleaned without stroking them first.
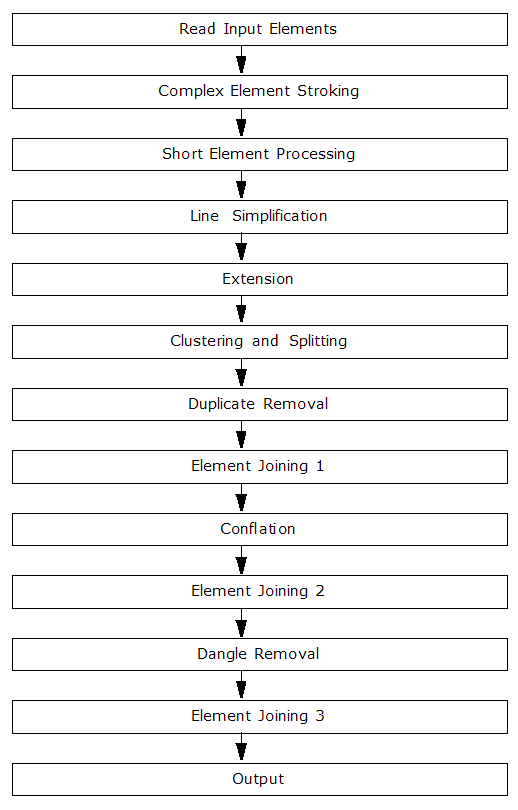
Module Workflow
MRFCleaner Modules provide more detailed information on the modules in the underlying MRFCleanFactory.
This ![]() default workflow
is suitable for most situations. However, using the individual modules,
it is possible to create any number of customized workflows for specific
projects and/or datasets (for example, in Workbench, by using a series
of consecutive MRFCleaner transformers or custom transformers). It is
important, however, to understand the data being processed and the desired
end result.
default workflow
is suitable for most situations. However, using the individual modules,
it is possible to create any number of customized workflows for specific
projects and/or datasets (for example, in Workbench, by using a series
of consecutive MRFCleaner transformers or custom transformers). It is
important, however, to understand the data being processed and the desired
end result.
More Information
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Transformer Categories
Search FME Knowledge Center
Search for samples and information about this transformer on the FME Knowledge Center.
Tags Keywords: MRFCleaner3D