Filters point, line, area, and text features based on spatial relationships. Each input Candidate feature is compared against all Filter features, based on the given spatial tests to meet. Features that pass any or all tests are output through the Passed port; all other features are output through the Failed port.
Typical Uses
- Dividing features, depending on whether a defined spatial relationship is true or false
- Performing quality control on a dataset by checking for expected spatial relationships with another dataset
- Performing a spatial join to transfer attributes from one feature to another based on their spatial relationship
How does it work?
The SpatialFilter compares two sets of features to see if their spatial relationships meet selected test conditions. The features being tested (Candidate features) are identified as having Passed or Failed the test.
For example, if you have a roads dataset (lines), and wanted to extract all the roads that passed through parks (polygons), you would direct the roads into the Candidate input port, and the parks into the Filter input port.
By selecting the test conditions Filter Intersects Candidate and Filter Contains Candidate, any road lines that fall within the parks or intersect the parks would be output via the Passed output port, and the remainder would exit through the Failed output port. You could simultaneously extract an attribute from the park polygon - park name, for example - and add it to the line feature.
In this example, we identify address points that are not contained by a building footprint. The results could be used to find bad address points, or identify missing building polygons.
The two source datasets look like this:
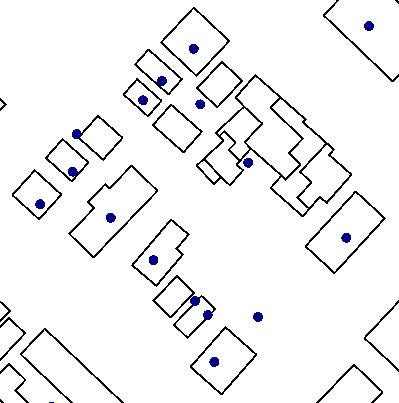
The address points - the dataset to be tested - are connected to the Candidate input port. The building footprints are connected to the Filter port, and provide the geometry that the address points will be tested against.
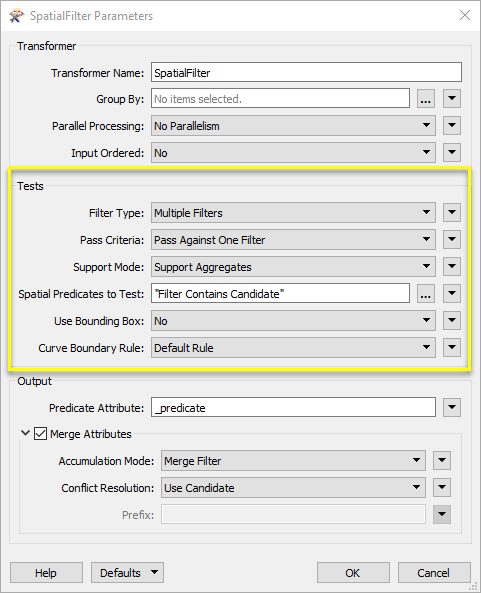
In the SpatialFilter parameters dialog, we make the following selections:
- Filter Type: Multiple Filters. There are multiple building polygons that we want to test against.
- Pass Criteria: Pass Against One Filter. Each address point only needs to fall inside one polygon - not all of them.
- Spatial Predicates to Test: Filter Contains Candidate. We want to check if each Candidate (address point) falls within a filter (building polygon).
These are the key parameters - the others are left as default for this example.
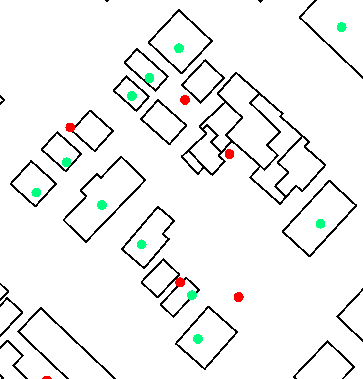
Address points that pass the test - that are within a polygon - are sent out through the Passed port, and have a new attribute called _predicate, set to “CONTAINS”.
Address points that fail the test - that are outside all polygons - are sent out through the Failed port. The results, with styling applied in the Data Inspector, look like this:
Usage Notes
- See Spatial Relations Defined for more information on spatial predicates and an illustration of spatial relationships.
Choosing a Spatial Transformer
Many transformers can assess spatial relationships and perform spatial joins - analyzing topology, merging attributes, and sometimes modifying geometry. Generally, choosing the one that is most specific to the task you need to accomplish will provide the optimal performance results. If there is more than one way to do it (which is frequently the case), time spent on performance testing alternate methods may be worthwhile.
To correctly analyze spatial relationships, all features should be in the same coordinate system. The Reprojector may be useful for reprojecting features within the workspace.
|
Transformer |
Can Merge Attributes |
Alters Geometry |
Counts Related Features |
Creates List |
Supported Types* |
Recommended For |
|---|---|---|---|---|---|---|
| SpatialFilter | Yes | No | No | No |
|
|
| SpatialRelator | Yes | No | Yes | Yes |
|
|
| AreaOnAreaOverlayer | Yes | Yes | Yes | Yes |
|
|
| LineOnAreaOverlayer | Yes | Yes | Yes | Yes |
|
|
| LineOnLineOverlayer | Yes | Yes | Yes | Yes |
|
|
| PointOnAreaOverlayer | Yes | No | Yes | Yes |
|
|
| PointOnLineOverlayer | Yes | Yes | Yes | Yes |
|
|
| PointOnPointOverlayer | Yes | No | Yes | Yes |
|
|
| Intersector | Yes | Yes | Yes | Yes |
|
|
| Clipper | Yes | Yes | No | No |
|
|
| NeighborFinder | Yes | In some cases | No | Yes |
|
|
| TopologyBuilder | Yes | Yes | No | Yes |
|
|
* NOTE: Curve includes Lines, Arcs, and Paths. Area includes Polygons, Donuts, and Ellipses.
Spatial analysis can be processing-intensive, particularly when a large number of features are involved. If you would like to tune the performance of your workspace, this is a good place to start.
When there are multiple ways to configure a workspace to reach the same goal, it is often best to choose the transformer most specifically suited to your task. As an example, when comparing address points to building polygons, there are a few ways to approach it.
The first example, using a SpatialFilter to test whether or not points fall inside polygons, produces the correct result. But the SpatialFilter is a fairly complex transformer, able to test for multiple conditions and accept a wide range of geometry types. It isn’t optimized for the specific spatial relationship we are analyzing here.
With a SpatialFilter:
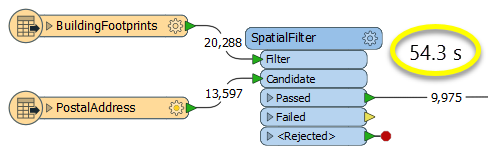
The second example uses a PointOnAreaOverlayer, followed by a Tester. The features output are the same as in the first method, but the transformer is optimized for this specific task. The difference in processing time is substantial - from 54.3 seconds in the first configuration, down to 13.7 seconds in the second one.
With a PointOnAreaOverlayer and a Tester:
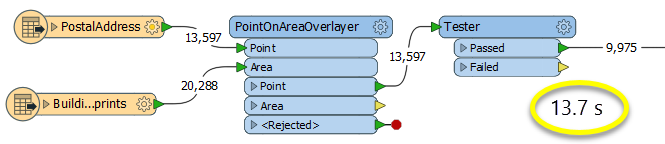
If performance is an issue in your workspace, look for alternative methods, guided by geometry.
Configuration
Input Ports
Point, line, area, and text features against which Candidates will be compared. These features are not output.
Point, line, area, and text features that will be tested against the Filter features.
Output Ports
Candidate features that successfully meet the test conditions selected in the parameters dialog.
Candidate features that do not meet the test conditions.
Filter and Candidate features with invalid geometries will be rejected and output via this port. If predicates are provided via an attribute, Candidate features with no or invalid predicates will also be output via this port.
Rejected features will have an fme_rejection_code attribute with one of the following values:
EXTRA_BASE_FEATURE
INVALID_BASE_GEOMETRY_NOT_OGC_VALID
INVALID_BASE_GEOMETRY_TYPE
INVALID_CANDIDATE_GEOMETRY_NOT_OGC_VALID
INVALID_CANDIDATE_GEOMETRY_TYPE
INVALID_CANDIDATE_PARAMETER_PREDICATE
INVALID_GEOMETRY_TYPE
MISSING_CANDIDATE_PARAMETER_PREDICATE
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
| Group By | If Group By attributes are specified, candidates are only compared against filters with the same values in these attributes. Both the Candidates and Filters must having matching attribute names and values. |
| Parallel Processing |
Select a level of parallel processing to apply. Default is No Parallelism. Note: How parallel processing works with FME: see About Parallel Processing for detailed information. This parameter determines whether or not the transformer should perform the work across parallel processes. If it is enabled, a process will be launched for each group specified by the Group By parameter. Parallel Processing LevelsFor example, on a quad-core machine, minimal parallelism will result in two simultaneous FME processes. Extreme parallelism on an 8-core machine would result in 16 simultaneous processes. You can experiment with this feature and view the information in the Windows Task Manager and the Workbench Log window. |
| Input Ordered |
No: This is the default behavior. Processing will only occur in this transformer once all input is present. By Group: This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger batch processing on the currently accumulating group. This will improve overall speed if groups are large/complex, but could cause undesired behavior if input groups are not truly ordered. Specifically, on a two input-port transformer, "in order" means that an entire group must reach both ports before the next group reaches either port, for the transformer to work as expected. This may take careful consideration in a workspace, and should not be confused with both port's input streams being ordered individually, but not synchronously. Using Ordered input can provide performance gains in some scenarios, however, it is not always preferable, or even possible. Consider the following when using it, with both one- and two-input transformers. Single Datasets/Feature Types: Are generally the optimal candidates for Ordered processing. If you know that the dataset is correctly ordered by the Group By attribute, using Input is Ordered By can improve performance, depending on the size and complexity of the data. If the input is coming from a database, using ORDER BY in a SQL statement to have the database pre-order the data can be an extremely effective way to improve performance. Consider using a Database Readers with a SQL statement, or the SQLCreator transformer. Multiple Datasets/Feature Types: Since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group, using Ordering with multiple feature types is more complicated than processing a single feature type. Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order. One approach is to send all features through a Sorter, sorting on the expected Group By attribute. The Sorter is a feature-holding transformer, collecting all input features, performing the sort, and then releasing them all. They can then be sent through an appropriate filter (TestFilter, AttributeFilter, GeometryFilter, or others), which are not feature-holding, and will release the features one at a time to the transformer using Input is Ordered By, now in the expected order. The processing overhead of sorting and filtering may negate the performance gains you will get from using Input is Ordered By. In this case, using Group By without using Input is Ordered By may be the equivalent and simpler approach. In all cases when using Input is Ordered By, if you are not sure that the incoming features are properly ordered, they should be sorted (if a single feature type), or sorted and then filtered (for more than one feature or geometry type). As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
| Filter Type |
Defines whether a single filter or multiple filters will be given, as well as clarifies the feature order that is expected.
|
| Pass Criteria | Specifies whether a candidate must have a predicate match against all Filters or against at least one Filter. |
| Support Mode |
Support Aggregates - both multis and aggregate geometries will be supported. However, the only supported predicates will be Contains, Disjoint, Equals, Intersects, Touches, and Within. The Overlaps predicate and the Crosses predicate will not be supported. 9-character masks representing Dimensionally Extended 9 Intersection Matrices will also not be supported. Support All Predicates - all the predicates described in the Spatial Relations Defined page will be supported. However, aggregate and multi geometries will not be supported. |
| Spatial Predicates to Test |
Defines which tests to perform. Choices include:
If the Support Mode is Support All Predicates, you may also test relationships using arbitrary 9-character masks. Such masks consist of the rows of a Dimensionally Extended 9 Intersection Matrix. Note that in order to use these masks with the SpatialFilter, you must assign them to an attribute on the Candidate features, and include the value of that attribute in the Tests to Perform clause (you cannot specify them directly). Multiple predicates may be specified in one attribute by separating them with a space. For more information about predicates, see Spatial Relations Defined. |
| Use Bounding Box | Defines whether the tests are performed using Candidate features' true coordinates or their bounding boxes. |
| Curve Boundary Rule | This attribute specifies how to determine the boundary of curve and multicurve geometries. The Default Rule is that any curve endpoints that occur an odd number of times in the geometry as a whole will be considered its boundary – that is, a linear loop (a line whose start point equals its endpoint) will not have any boundary. The other rule specifies that the curve's or multicurve's boundary is the set of all its endpoints. |
| Predicate Attribute | Specifies an attribute that will be added onto all output Passed features, which will contain the name of the spatial test that the feature passed. |
| Merge Attributes | Defines whether attribute merging will take place. If this is enabled, every Candidate that matches a Filter receives that Filter's attributes. The result is an operation known as a Spatial Join. |
| Accumulation Mode |
Enabled if merging attributes. Options include:
|
| Conflict Resolution |
Enabled if merging attributes. Options include:
|
| Prefix | Enabled if merging attributes and Accumulation Mode is set to Prefix Filter. Defines a prefix to add onto all attributes that are merged from Filters to Candidates. |
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters. There are a number of tools and shortcuts that can assist in constructing values, generally available from the drop-down context menu adjacent to the value field.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more - whether entered directly in a parameter or constructed using one of the editors.
| These functions manipulate and format strings. | |
| A set of control characters is available in the Text Editor. | |
| Math functions are available in both editors. | |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Working with User Parameters | Create your own editable parameters. |
Reference
|
Processing Behavior |
|
|
Feature Holding |
Yes |
| Dependencies | |
| FME Licensing Level | FME Base Edition and above |
| Aliases | |
| History | |
| Categories |
FME Knowledge Center
The FME Knowledge Center is the place for demos, how-tos, articles, FAQs, and more. Get answers to your questions, learn from other users, and suggest, vote, and comment on new features.
Search for all results about the SpatialFilter on the FME Knowledge Center.
Examples may contain information licensed under the Open Government Licence – Vancouver