Determines the density of a group of Candidate features.
Density is a measurement of Candidate values per unit area. It is calculated as a numeric value; the greater the value, the more dense are the Candidate features.
The density equation is Total Candidates/Area of Interest.
Total Candidates is defined by either:
- The total NUMBER of Candidate features
- The sum LENGTH of Candidate features
- The sum Area of Candidate features
Area of Interest is defined by the size of the first polygon feature that enters the Area input port.
Caution
It’s VERY important to note that ALL Candidate features count towards the density calculation, even if they fall outside the Area feature.
In other words, this transformer does not test whether or not candidate objects are inside the Area feature. If you wish to use only Candidate features that lie within, or overlap, the Area feature, you should pre-process the data using either a SpatialFilter or SpatialRelator transformer.
Input Ports
A single reference feature covering the area of interest.
A series of Candidate features.
Output Ports
The original Area feature(s) with the Density Attribute added. Its value will be the sum of the corresponding Candidate features (their number, length, or area) divided by the area of this feature itself.
The original Candidate features with the Density Attribute added. Each Candidate in a group will receive the same density value: the sum of the Candidate features in that group divided by the area of the first corresponding Area feature.
Parameters
Transformer
If this parameter is not specified, then ALL Candidate features form a single group, and are processed against a single Area feature. This is the default behavior.
When an attribute is specified for this parameter, then groups are formed where they have matching attribute values. This allows you to process multiple groups of Candidate features against multiple Area features.
Note: How parallel processing works with FME: see About Parallel Processing for detailed information.
This parameter determines whether or not the transformer should perform the work across parallel processes. If it is enabled, a process will be launched for each group specified by the Group By parameter.
Parallel Processing Levels
For example, on a quad-core machine, minimal parallelism will result in two simultaneous FME processes. Extreme parallelism on an 8-core machine would result in 16 simultaneous processes.
You can experiment with this feature and view the information in the Windows Task Manager and the Workbench Log window.
No: This is the default behavior. Processing will only occur in this transformer once all input is present.
By Group: This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger batch processing on the currently accumulating group. This will improve overall speed if groups are large/complex, but could cause undesired behavior if input groups are not truly ordered.
Using Ordered input can provide performance gains in some scenarios, however, it is not always preferable, or even possible. Consider the following when using it, with both one- and two-input transformers.
Single Datasets/Feature Types: Are generally the optimal candidates for Ordered processing. If you know that the dataset is correctly ordered by the Group By attribute, using Input is Ordered By can improve performance, depending on the size and complexity of the data.
If the input is coming from a database, using ORDER BY in a SQL statement to have the database pre-order the data can be an extremely effective way to improve performance. Consider using a Database Readers with a SQL statement, or the SQLCreator transformer.
Multiple Datasets/Feature Types: Since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group, using Ordering with multiple feature types is more complicated than processing a single feature type.
Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
One approach is to send all features through a Sorter, sorting on the expected Group By attribute. The Sorter is a feature-holding transformer, collecting all input features, performing the sort, and then releasing them all. They can then be sent through an appropriate filter (TestFilter, AttributeFilter, GeometryFilter, or others), which are not feature-holding, and will release the features one at a time to the transformer using Input is Ordered By, now in the expected order.
The processing overhead of sorting and filtering may negate the performance gains you will get from using Input is Ordered By. In this case, using Group By without using Input is Ordered By may be the equivalent and simpler approach.
In all cases when using Input is Ordered By, if you are not sure that the incoming features are properly ordered, they should be sorted (if a single feature type), or sorted and then filtered (for more than one feature or geometry type).
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains.
Parameters
This parameter determines how the total candidates value is calculated. Its possible values are:
- Number of Features
- Line Length
- Area
Typically, the relationship between this parameter and Candidate geometry is as follows:
| Candidate Geometry | Calculate Density By |
|---|---|
| Points | Number of Features |
| Lines | Line Length |
| Polygon (Area) | Area |
When the Candidate geometry does not match what is required – for example, point features when Calculate Density By equals Area – then the features are ignored (but still output).
This parameter defines the attribute that is to receive the calculated density value. The default is _density.
Usage Notes
- The geometry type of Candidate features may be points, lines, or polygons. However, Area features must be polygons.
- If excess Area features are supplied – i.e. there is more than one Area feature for a particular group – then they are excluded from the calculation of density for Candidates. However, they will still receive their own density calculation. In other words, each Area receives the density of Candidate features for their own size; but Candidate features only receive their density in relation to the size of the first Area feature.
- If you need to find the density of Candidate features against the total area of a number of polygon features, use an Aggregator to aggregate the polygons and input the resulting aggregate to the Area port of this transformer.
Example
There are many possible uses for this transformer, including:
Density of disease (number of incidences per km2)
Density of traffic network (amount of road length per km2)
Density of land use (amount of industrial zoning per km2)
In this example, the density of cycle route network is calculated for a particular zipcode (postal code).
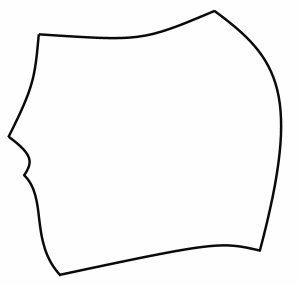
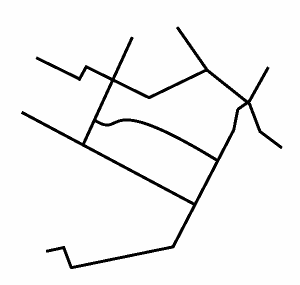
Area of zipcode: 195355642.75 ft2
Total length of cycle route: 83017.28 ft
Density: 0.000425
In this example, the cycle routes spatially overlap with the zipcode boundaries, and are clipped to match, but the DensityCalculator does not necessarily need this to be so.
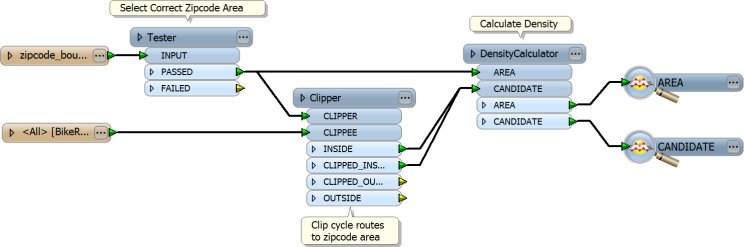
If there were multiple zipcode features to be processed, then a group-by could be used in the DensityCalculator, using the zipcode attribute as the attribute to group-by. The result would be a count of the cycle route density for each zipcode.
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Transformer Categories
FME Licensing Level
FME Professional edition and above
Search FME Knowledge Center
Search for samples and information about this transformer on the FME Knowledge Center.