Creates a buffer zone of specified size around or inside input geometry.
Typical Uses
- Creating fixed size zones around features, such as rights-of-way or setbacks
- Determining spatial relationships based on proximity
- Creating variable size zones around features to represent attribute values
How does it work?
The Bufferer accepts 2D point, curve (line), and area geometries.
Point and lines may be expanded, creating surrounding polygons with points offset by the specified Buffer Amount in ground units. Areas may be expanded or shrunk, using positive or negative Buffer Amounts.
The attributes of the original features are retained, and the buffer is output, discarding the original geometry.
A selection of end cap and corner styles is available.
An optional list attribute may be created, holding multiple attributes for grouped or aggregate input.
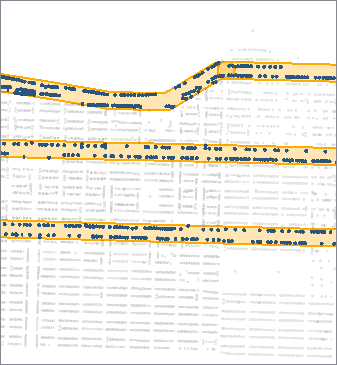
In this example, we buffer arterial streets (shown in blue) to find address points that fall within a fixed distance of them.
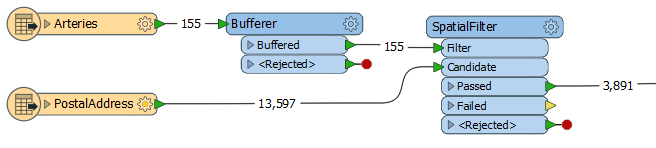
The arteries are routed into a Bufferer.
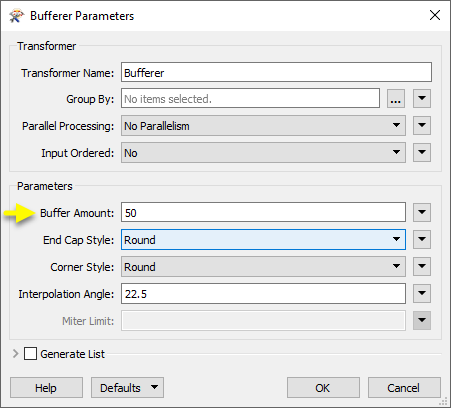
We enter a Buffer Amount of 50 - representing 50 meters, as our data is in a UTM projection with ground units in meters.
The buffered streets are then sent to a SpatialFilter, along with the address points, and are tested for points that fall within the buffers.
In this example, we take a point dataset of food carts that has an attribute containing the average number of daily customers they serve. We route the points into the Bufferer.

A bit of experimentation shows that dividing the daily traffic numbers by 10 will produce a desirable range of bubble sizes, and so we set the Buffer Amount to the value of the DAILY_TRAF attribute, divided by 10.
The resulting buffers are colored according to the category of food cart (type of food served).

Usage Notes
- This transformer creates buffers that are of equal width on either side of a linear input feature. To create offsets to either the left or right-hand side of a feature, use the OffsetCurveGenerator.
- To buffer features in Geographic (lat/long) coordinates, consider the GeographicBufferer.
- Areas will be buffered on one side only - externally for a positive Buffer Amount, and internally for a negative Buffer Amount.
Configuration
Input Ports
Points, curves (lines), or areas. Only 2D geometries are accepted as input.
Output Ports
Each point in the output curve will be the specified amount, measured in ground units, away from the input geometry. If the specified buffer amount is too small, a feature with a null geometry is output.
The original geometry is not output.
Features without point, curve, or area geometries are output through this port along with an additional attribute, fme_rejection_code, to indicate the reason for rejection.
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
| Group By | The default behavior is to use the entire set of features as the group. This option allows you to select attributes that define which groups to form. |
| Parallel Processing |
Select a level of parallel processing to apply. Default is No Parallelism. Note: How parallel processing works with FME: see About Parallel Processing for detailed information. This parameter determines whether or not the transformer should perform the work across parallel processes. If it is enabled, a process will be launched for each group specified by the Group By parameter. Parallel Processing LevelsFor example, on a quad-core machine, minimal parallelism will result in two simultaneous FME processes. Extreme parallelism on an 8-core machine would result in 16 simultaneous processes. You can experiment with this feature and view the information in the Windows Task Manager and the Workbench Log window. |
| Input Ordered |
No: This is the default behavior. Processing will only occur in this transformer once all input is present. By Group: This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger batch processing on the currently accumulating group. This will improve overall speed if groups are large/complex, but could cause undesired behavior if input groups are not truly ordered. Specifically, on a two input-port transformer, "in order" means that an entire group must reach both ports before the next group reaches either port, for the transformer to work as expected. This may take careful consideration in a workspace, and should not be confused with both port's input streams being ordered individually, but not synchronously. Using Ordered input can provide performance gains in some scenarios, however, it is not always preferable, or even possible. Consider the following when using it, with both one- and two-input transformers. Single Datasets/Feature Types: Are generally the optimal candidates for Ordered processing. If you know that the dataset is correctly ordered by the Group By attribute, using Input is Ordered By can improve performance, depending on the size and complexity of the data. If the input is coming from a database, using ORDER BY in a SQL statement to have the database pre-order the data can be an extremely effective way to improve performance. Consider using a Database Readers with a SQL statement, or the SQLCreator transformer. Multiple Datasets/Feature Types: Since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group, using Ordering with multiple feature types is more complicated than processing a single feature type. Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order. One approach is to send all features through a Sorter, sorting on the expected Group By attribute. The Sorter is a feature-holding transformer, collecting all input features, performing the sort, and then releasing them all. They can then be sent through an appropriate filter (TestFilter, AttributeFilter, GeometryFilter, or others), which are not feature-holding, and will release the features one at a time to the transformer using Input is Ordered By, now in the expected order. The processing overhead of sorting and filtering may negate the performance gains you will get from using Input is Ordered By. In this case, using Group By without using Input is Ordered By may be the equivalent and simpler approach. In all cases when using Input is Ordered By, if you are not sure that the incoming features are properly ordered, they should be sorted (if a single feature type), or sorted and then filtered (for more than one feature or geometry type). As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
| Buffer Amount |
Each point in the output curve is the specified amount, measured in ground units, away from the input geometry.
|
| End Cap Style |
When buffering a line, you can specify the end-cap style. As these diagrams illustrate, these caps can be Round (default) or Square, but you can also set this parameter to None. Round
Square
None
|
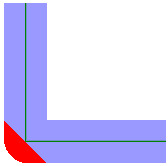
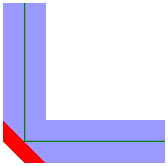
| Corner Style |
When buffering a line or area, you can specify the corner style. As the diagrams below illustrate, the corner styles can be Round (default), Bevel (chopped), or Miter (pointed). If Miter is used, a limit must be specified using the Miter Limit parameter. If a corner is too pointed for the miter limit, the corner will instead be bevelled. Round
Bevel
Miter
|
| Interpolation Angle |
This parameter controls the smoothness of the stroked arcs in the output buffer boundaries. It specifies what angles should be used to construct a circular arc. As this parameter decreases in value, the smoothness of the arc connectors increases. This parameter is used for the Round End Cap Style and the Round Corner Style. The value must be between 0 and 90 degrees. |
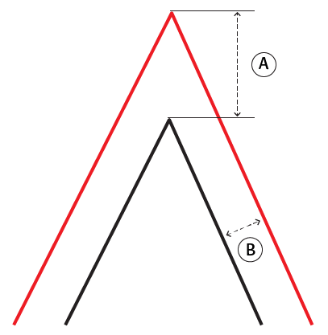
| Miter Limit |
Miter Limit This parameter controls how pointed a buffered corner can be before it is beveled. It is the highest value that the ratio of corner distance to offset is allowed to have before truncation occurs. A higher number allows for more extreme corner angles.
Miter Ratio = Corner distance / Offset
|




Generate List
When enabled, adds a list attribute to the Buffered output features. This parameter is useful when using Group By or if input features contain aggregates. Within each group or aggregate, within each dissolved region, attributes from an input feature with the largest area are stored at the head of the list, and no order is defined for the remaining elements.
| List Name |
Enter a name for the list attribute. Note: List attributes are not accessible from the output schema in Workbench unless they are first processed using a transformer that operates on them, such as ListExploder or ListConcatenator. All list attribute transformers are displayed in the Contents pane of the Transformer Help under Lists. Alternatively, AttributeExposer can be used. |
| Add To List |
All Attributes: All attributes will be added to the output features. Selected Attributes: Enables the Selected Attributes parameter, where specific attributes may be chosen for inclusion. |
| Selected Attributes | Enabled when Add To List is set to Selected Attributes. Specify the attributes you wish to be included. |
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters. There are a number of tools and shortcuts that can assist in constructing values, generally available from the drop-down context menu adjacent to the value field.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more - whether entered directly in a parameter or constructed using one of the editors.
| These functions manipulate and format strings. | |
| A set of control characters is available in the Text Editor. | |
| Math functions are available in both editors. | |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Working with User Parameters | Create your own editable parameters. |
Reference
|
Processing Behavior |
Dependent on Group By parameter. If:
|
|
Feature Holding |
Dependent on Group By parameter. If:
|
| Dependencies | |
| FME Licensing Level | FME Base Edition and above |
| Aliases | |
| History | |
| Categories |
FME Knowledge Center
The FME Knowledge Center is the place for demos, how-tos, articles, FAQs, and more. Get answers to your questions, learn from other users, and suggest, vote, and comment on new features.
Search for all results about the Bufferer on the FME Knowledge Center.
Examples may contain information licensed under the Open Government Licence – Vancouver