In this example, we have a point dataset of food vendors and a set of polygons representing neighborhoods.
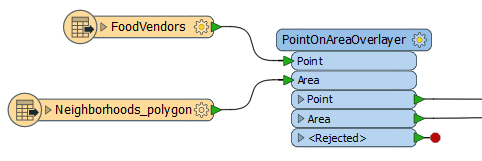
To find which neighborhood a vendor is in, we connect the food vendor points to the Point input port, and the neighborhoods to the Area input port.
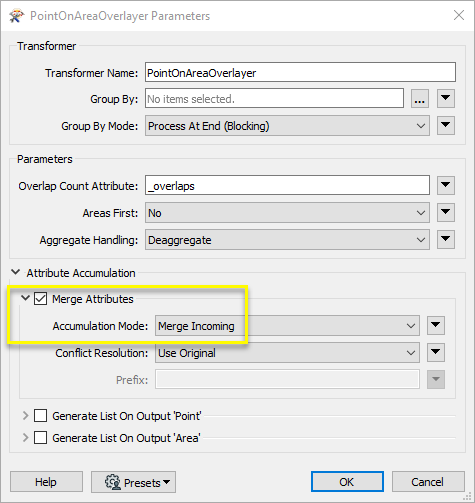
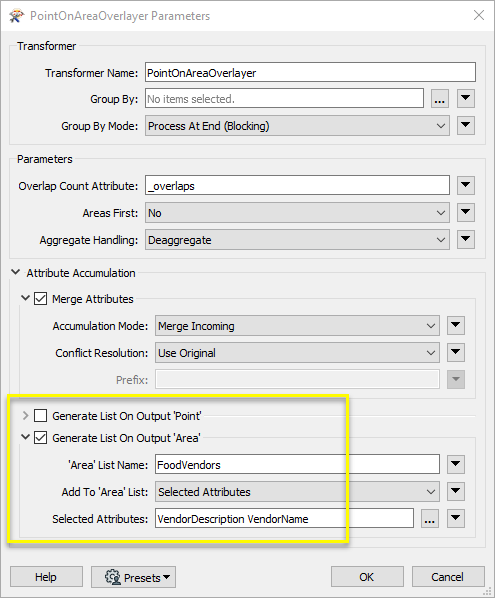
In the parameters dialog, the default settings will provide the correct results. Note that the Attribute > Accumulation Mode is set to Incoming, which will add attributes from the containing neighborhood polygon to each point.
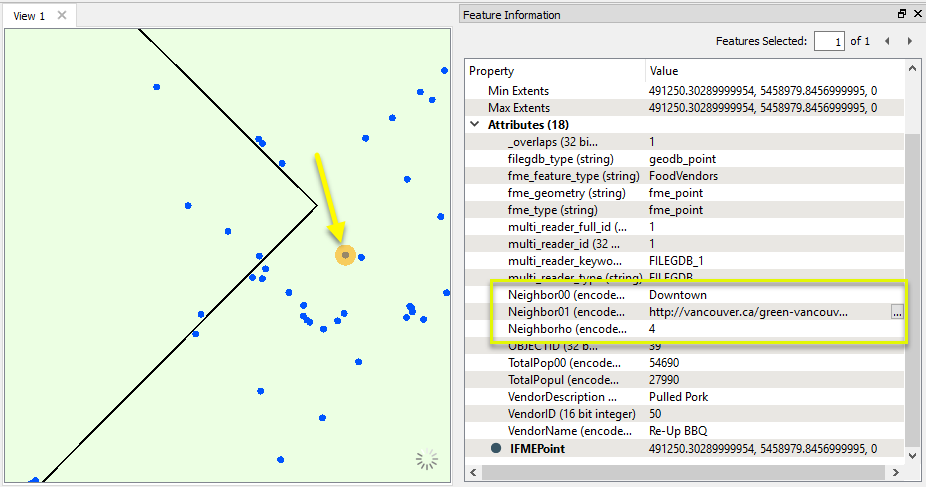
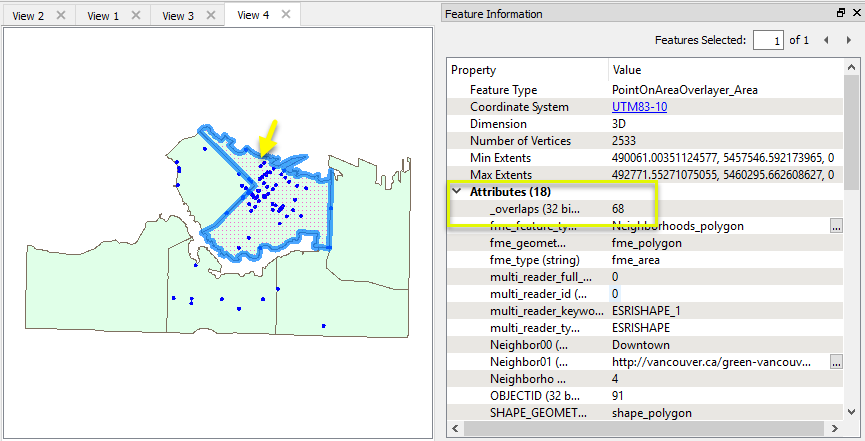
Looking at the food vendor points output, we can see that the containing neighborhood attributes have been added.
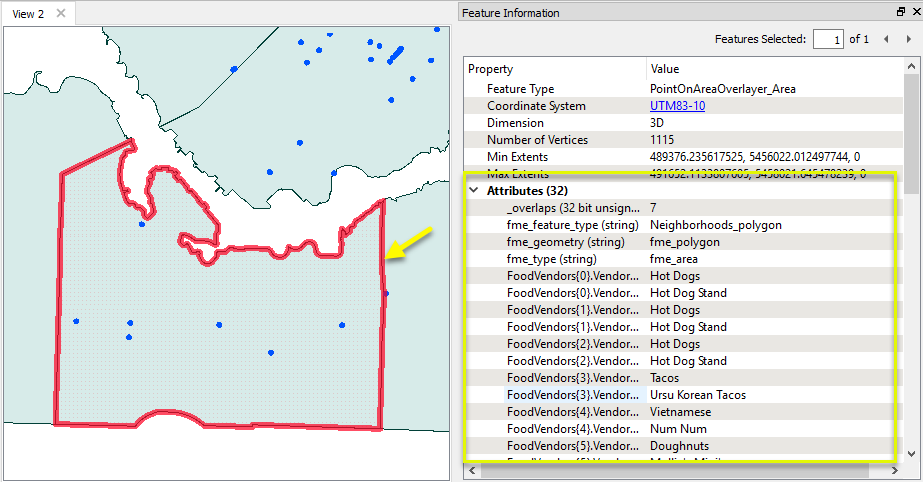
Looking at the area output, the _overlaps attribute tells us how many food vendors exist in each neighborhood.
 beside the applicable parameter. For more information, see
beside the applicable parameter. For more information, see