NeighborFinder
Finds the nearest Candidate feature(s) to each Base feature and merges their attributes onto the Base feature. May also be used in Candidates Only mode, where each feature is considered the Base in turn and compared to all other features, but not itself.
Jump to Configuration
Typical Uses
- Identifying the nearest feature(s)
- Identifying features within a specified distance
- Adding a point closest to a candidate (such as adding a point on a railway track at the closest point to a station)
- Finding the closest feature in a certain direction (by filtering the resulting candidate angle)
- Calculating clusters or density by counting neighbors within a set distance
How does it work?
The NeighborFinder generally takes in two sets of features - Base and Candidate. For each Base feature, the transformer checks the Candidates for matches, based on proximity and parameter selections. It may check for the closest Candidate feature, or a fixed maximum number of closest Candidates, or all Candidates that fall within a specified distance of the Base feature.
Attributes from one matching Candidate are added to the Base features, including:
- Attributes from matching Candidate
- Calculated attributes containing distance, angle, and coordinates of matches
- Coordinates of the interpolated point on the Base that is closest to the Candidate
Attributes from multiple matching Candidates may be stored in a List attribute.
Output includes Matched Base features with these new attributes, Unmatched Base features (unchanged), and Unmatched Candidates (unchanged).
The NeighborFinder works with 2D geometries only; if an input geometry is 3D, its z-coordinate will be ignored. The transformer has full support for points, lines, arcs, ellipses, polygons, and donuts, and has limited support for other types of geometry. Polygons, ellipses and donuts may be processed as lines or areas, depending on user selection.
Candidates Only Mode
The NeighborFinder can be used in a Candidates Only mode, in which only Candidate input features are considered. In this mode, each feature is considered the Base in turn, and compared to all other Candidates (but not itself). Attribute sharing and Output behavior are the same as above.
Candidates-Only Mode is enabled with the Input parameter. When Input is set to Candidates Only, the Base input port is removed.
 Example: Finding the nearest match
Example: Finding the nearest match
In this example, we have a set of parcel polygons with no useful attributes, and a point dataset intended for labeling, with address attributes. We want to extract the addresses and apply them to the parcel polygons.
Though a PointOnAreaOverlayer would perform a similar comparison, it wouldn’t find a match where the point falls just outside the polygon, as in #1132. We will use a NeighborFinder.
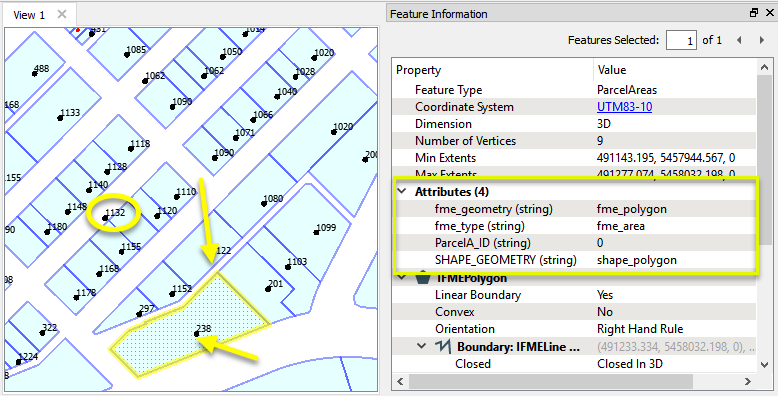
The parcel polygons are routed into a NeighborFinder as the Base features - the ones that the transformer will try to find matches for.
The address points are connected as the Candidates - the ones that will be searched for a match, and will then supply the new attributes to the Base features.
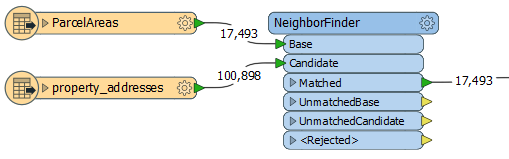
In the Parameters dialog, Number of Neighbors to Find is set to 1, as we want only the single closest match to be used. Treat Polygons As is set to Areas.
Note that the default setting for Accumulation Mode - Merge Candidate - will copy the Candidate’s attributes onto the Base feature (which is what we want).
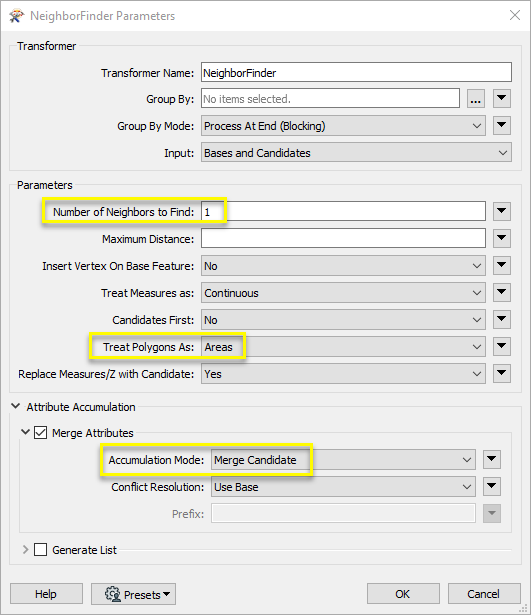
The output Matched parcel polygons now have attributes from their closest Candidate match.
Example: Finding all matches within a set distance
In this example, we have a dataset of bike path lines, and want to find drinking water fountains within 100 meters of the paths.
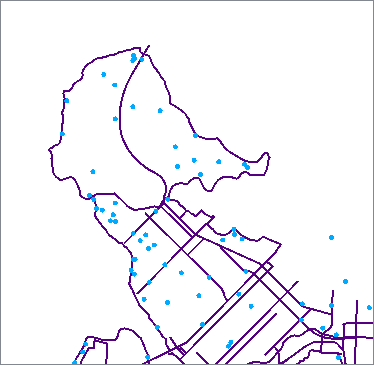
The bike paths are routed into a NeighborFinder as the Base features - the ones that the transformer will try to find matches for, and output.
The water fountain points are connected as the Candidates - the ones that will be searched for matches, and will then supply attributes to the Base features, as a list.
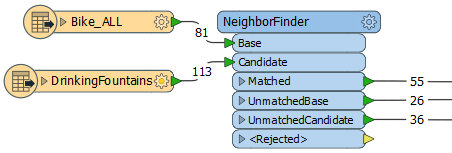
In the Parameters dialog, Number of Neighbors to Find is blank, and so no limit is imposed and all matches will be recorded. Maximum Distance is set to 100 (ground units, here in meters.)
By enabling Generate List and selecting specific attributes from the drinking fountain data, a list attribute will be added to the bike paths to store multiple matches.
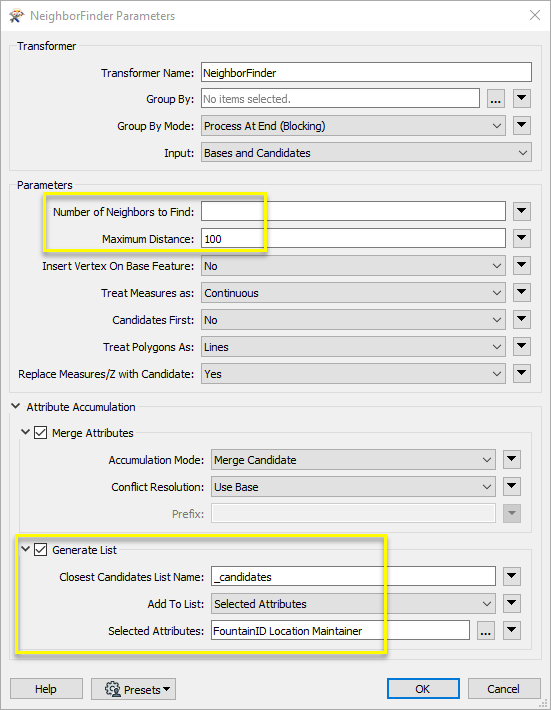
One item is added to the _candidates list attribute for each match, as shown on the selected feature here. The list can be further manipulated to work with this information - see List Attributes.
Choosing a Spatial Transformer
Many transformers can assess spatial relationships and perform spatial joins - analyzing topology, merging attributes, and sometimes modifying geometry. Generally, choosing the one that is most specific to the task you need to accomplish will provide the optimal performance results. If there is more than one way to do it (which is frequently the case), time spent on performance testing alternate methods may be worthwhile.
To correctly analyze spatial relationships, all features should be in the same coordinate system. The Reprojector may be useful for reprojecting features within the workspace.
Spatial Transformers Comparison Matrix
| SpatialFilter
|
Yes |
No |
No |
No |
|
-
Testing for the existence of spatial relationships between two sets of features, and routing them according to whether they pass or fail the test(s).
|
| SpatialRelator |
Yes |
No |
Yes |
Yes |
|
-
Identifying the nature of spatial relationships between two sets of features.
|
| AreaOnAreaOverlayer
|
Yes |
Yes |
Yes |
Yes |
|
-
Finding polygon overlaps and extracting them into new geometry.
|
| LineOnAreaOverlayer
|
Yes |
Yes |
Yes |
Yes |
|
-
Finding intersections between lines and polygons, and splitting the lines where they intersect with the polygons.
|
| LineOnLineOverlayer
|
Yes |
Yes |
Yes |
Yes |
|
-
Finding intersections between line features, splitting them, and generating new line geometry as well as points representing the intersections.
|
| PointOnAreaOverlayer
|
Yes |
No |
Yes |
Yes |
- Point and Area
- Text and Area
|
-
Identifying points that fall within polygons, and merging attributes between them
|
| PointOnLineOverlayer
|
Yes |
Yes |
Yes |
Yes |
-
Point and Curve
- Text and Curve
|
-
Identifying where points fall on lines, and splitting the lines into new geometry.
|
| PointOnPointOverlayer
|
Yes |
No |
Yes |
Yes |
|
- Identifying points in the same location (within a tolerance), and merging attributes between them.
|
| Intersector
|
Yes |
Yes |
Yes |
Yes |
|
-
Finding intersections between all input features, regardless of geometry (optionally including self-intersections), splitting features, and creating new geometry.
|
| Clipper
|
Yes |
Yes |
No |
No |
- Point
- Text
- Curve
- Area
- Solids
- Raster
- Point Cloud
|
-
Comparing features against a set of Clipper features, and splitting the features at or along the Clipper boundaries. Outputs both new and untouched geometry, identified as either Inside or Outside the Clipper.
|
| NeighborFinder
|
Yes |
In some cases |
No |
Yes |
|
-
Identifying the nearest other feature(s) to each feature being considered, either in another set of features or within the same feature set.
|
| TopologyBuilder
|
Yes |
Yes |
No |
Yes |
|
- Analyzing spatial relationships between features to compute topology, splitting features and creating new geometry representing topologically significant nodes, edges, and faces, with associated attributes.
|
* NOTE: Curve includes Lines, Arcs, and Paths. Area includes Polygons, Donuts, and Ellipses.
The Effect of Spatial Transformer Choice on Performance
Spatial analysis can be processing-intensive, particularly when a large number of features are involved. If you would like to tune the performance of your workspace, this is a good place to start.
When there are multiple ways to configure a workspace to reach the same goal, it is often best to choose the transformer most specifically suited to your task. As an example, when comparing address points to building polygons, there are a few ways to approach it.
The first example, using a SpatialFilter to test whether or not points fall inside polygons, produces the correct result. But the SpatialFilter is a fairly complex transformer, able to test for multiple conditions and accept a wide range of geometry types. It isn’t optimized for the specific spatial relationship we are analyzing here.
With a SpatialFilter:
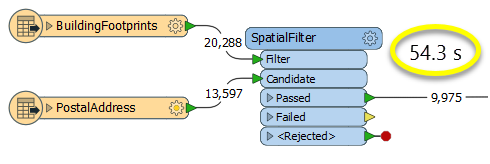
The second example uses a PointOnAreaOverlayer, followed by a Tester. The features output are the same as in the first method, but the transformer is optimized for this specific task. The difference in processing time is substantial - from 54.3 seconds in the first configuration, down to 13.7 seconds in the second one.
With a PointOnAreaOverlayer and a Tester:
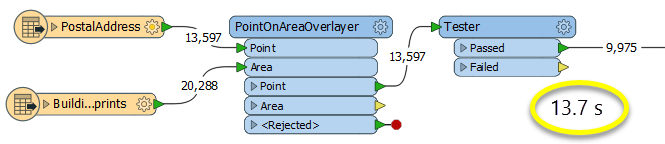
If performance is an issue in your workspace, look for alternative methods, guided by geometry.
Configuration
Input Ports
If a feature is routed to both the Base and the Candidate input ports,
then features will be compared to themselves as they are both a Base and
Candidate.
If Input is set to Candidates Only, there will be no Base port. All Candidates will be compared
with all other Candidates, but will not be compared to themselves.
Base
Features to receive attributes from matching Candidates, according to the parameters defined in the transformer, and to be kept as output.
Candidate
Features that will provide attributes if they match the conditions defined. Candidates are not output.
In Candidates-Only mode (Input parameter set to Candidates Only), Candidates will behave as both Candidate and Base, and so will also receive attributes from matches and be output.
Output Ports
Matched
If a Candidate feature is found, then all the attributes from the closest Candidate feature are added to the Base feature and the Base feature is output via the Matched port.
If Generate List is enabled, either all or selected attributes from multiple matching Candidates may be added to a new list attribute.
In addition, several other attributes are added to the Base feature just prior to it being output via the Matched port:
| Attributes |
Description |
| _distance |
The distance from the Base to the matching Candidate |
| _angle |
The angle between the closest interpolated Base point and the closest
interpolated Candidate point. |
| _closest_base_x,
_closest_base_y |
The coordinates of the closest interpolated point on the Base feature relative
to the Candidate feature.
|
| _closest_candidate_x,
_closest_candidate_y |
The coordinates of the closest interpolated point on the Candidate feature
relative to the Base feature.
|
| _candidate_angle |
The angle from (_closest_candidate_x, _closest_candidate_y) to the next vertex
within the Candidate feature. If (_closest_candidate_x, _closest_candidate_y)
equals the last vertex of the Candidate feature, then candidate_angle will be
the angle from the previous vertex of the Candidate feature to
(_closest_candidate_x, _closest_candidate_y).
|
| _candidate_label_angle |
The _candidate_angle adjusted so that if it is used as a text rotation,
the text will run from left to right. This
angle is guaranteed to be greater than or equal to 270 and less than 360,
or greater than or equal to 0 and less than or equal to 90. |
All angles are measured in degrees counterclockwise from horizontal. Where angles are not well-defined (for example, when a Candidate polygon is contained inside a Base polygon), they are set to 0.

UnmatchedBase
If there are no Candidate features found to be within the maximum distance,
then the Base feature will be output unchanged via the UnmatchedBase
port.
UnmatchedCandidate
Candidate features not within the Maximum Distance to any Base feature are output via the UnmatchedCandidate port. Candidate features in excess of the Number of Neighbors to Find parameter will also be output here (only the first x number of matches will be used).
If Generate List is not enabled, then any features within the Maximum Distance, but not closest, will be output from the UnmatchedCandidate port. This is because they are not used in any way; their attributes are not merged onto the base at all.
<Rejected>
Invalid features are output via the <Rejected> port. Base and candidate features with null geometry will be rejected. Features with invalid geometries may also be rejected.
Rejected features will have an fme_rejection_code attribute with one of the following values:
EXTRA_CANDIDATE_FEATURE
INVALID_BASE_GEOMETRY_VERTICES
INVALID_CANDIDATE_GEOMETRY_VERTICES
INVALID_GEOMETRY_VERTICES
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
Transformer
| Group By
|
The default behavior is to use the entire set of features as the group. This option allows you to select attributes that define which groups to form. |
| Group By Mode
|
Process At End (Blocking): This is the default behavior. Processing will only occur in this transformer once all input is present.
Process When Group Changes (Advanced): This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger processing on the currently accumulating group. This may improve overall speed (particularly with multiple, equally-sized groups), but could cause undesired behavior if input groups are not truly ordered.
Considerations for Using Group By
There are two typical reasons for using Process When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations.
The second possible reason is potential performance gains.
Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains).
Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with Process At End (Blocking) may be the equivalent and simpler approach.
Note: Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains.
|
| Input
|
Bases and Candidates - Accepts both Base and Candidate features (default).
If a feature is routed to both the Base and the Candidate input ports, then features will be compared to themselves as they are both a Base and Candidate.
Candidates Only - Accept only Candidate features. There will be no Base input port. All Candidates will be compared with all other Candidates, but will not be compared to themselves.
|
Parameters
| Number of Neighbors to Find
|
The maximum number of Candidate features that will be included in the list specified by the Generate List parameter. The closest candidate features will be included in the list.
If the value is 0 or blank, there is no limit to the number of neighbors that will be included in the list.
|
| Maximum Distance
|
The Maximum Distance is measured in the units of coordinates of the input features.
The list specified in Generate List contains all of the Candidate features that were within the Maximum Distance of the Base. Candidates exactly at the maximum distance will be included in the Closest Candidate List.
If the value is 0 or blank, no limit will be put on the maximum distance.
|
| Insert Vertex On Base Feature
|
If Yes, then (_closest_base_x, _closest_base_y) will be inserted onto the Base feature if the insertion is well-defined. For example, if a Candidate polygon is contained inside a Base polygon, insertion will not take place.
If Yes, the _closest_base_x, _closest_base_y vertex will be inserted onto to the Base feature as well as added as an attribute. This option only applies to Lines, Polygons, Paths, Arcs, Ellipses, and Donuts.
|
| Treat Measures as
|
Measures added to the base can be treated as Discrete, meaning that they will be taken from the nearest known measure value, or Continuous, meaning that they will be interpolated from the nearest points.
|
| Candidates First
|
If Yes, then all Candidate features must be input before any Base features. If a Candidate feature is input after a Base feature and this option is set to Yes, the Candidate feature will be ignored in all calculations.
|
| Treat Polygons As
|
Lines: A polygon, donut, or ellipse will be treated as a line (that is, its boundary line) for backwards compatibility.
Areas: A polygon, donut, or ellipse will be treated as an area, and any geometry that overlaps with the area will be of 0 distance away from that area.
|
| Replace Measures/Z with Candidate
|
If the candidate is a line, and the base is a point, this will specify if measures and z values should be copied from the candidate to the base. The z values will be equal to the interpolated z values at the point on the candidate that is closest to the base. The measures will either be interpolated or use the nearest known measure value, depending on the Treat Measures as parameter.
If the candidate is not a line, or the base is not a point, this will have no effect.
|
Attribute Accumulation
If attributes on the Base and Candidate feature share the same name, but are not geometry attributes that start with fme_, then they are deemed conflicted.
| Accumulation Mode
|
Merge Candidate: The base feature will retain all of its own un-conflicted attributes, and will additionally acquire any un-conflicted attributes that the candidate feature has. This mode will handle conflicted attributes based on the Conflict Resolution parameter. Prefix Candidate: The base feature will retain all of its own attributes. In addition, the base will acquire attributes reflecting the candidate feature’s attributes, with the name prefixed with the Prefix parameter. Only Use Candidate: The base feature will have all of its attributes removed, except geometry attributes that start with fme_. Then, all of the attributes from one (arbitrary) candidate feature will be placed onto the base. |
| Conflict Resolution
|
Use Base: If a conflict occurs, the base values will be maintained. Use Candidate: If a conflict occurs, the values of the candidate will be transferred onto the base. |
| Prefix
|
To prevent a Candidate attribute from being ignored because the Base attribute already exists, you can optionally specify a prefix that will be applied to each Candidate attribute when it is added to the Base. This parameter is only enabled when the Accumulation Mode is Prefix Candidate. |
Generate List
When enabled, adds a list attribute to the Matched output features. This parameter is useful when the Number of Neighbors to Find is greater than 1.
| Closest Candidates List Name
|
Enter a name for the list attribute.
Note: List attributes are not accessible from the output schema in Workbench unless they are first processed using a transformer that operates on them, such as ListExploder or ListConcatenator. Alternatively, AttributeExposer can be used.
|
| Add To List
|
All Attributes: All attributes will be added to the output features.
Selected Attributes: Enables the Selected Attributes parameter, where specific attributes may be chosen for inclusion.
|
| Selected Attributes
|
Enabled when Add To List is set to Selected Attributes. Specify the attributes you wish to be included.
|
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters. There are a number of tools and shortcuts that can assist in constructing values, generally available from the drop-down context menu adjacent to the value field.
How to Set Parameter Values
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Text Editor
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Arithmetic Editor
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more - whether entered directly in a parameter or constructed using one of the editors.
Reference
|
Processing Behavior
|
Group-Based
|
|
Feature Holding
|
Yes
|
| Dependencies |
|
|
FME Licensing Level
|
FME Professional Edition and above
|
| Aliases |
NeighbourFinder
|
| History |
|
| Categories |
Spatial Analysis
|
FME Community
The FME Community is the place for demos, how-tos, articles, FAQs, and more. Get answers to your questions, learn from other users, and suggest, vote, and comment on new features.
Search for all results about the NeighborFinder on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver