FME Transformers: 2026.2
Categories
Workflows
Executes a user-supplied Python script to manipulate features.
Typical Uses
- Tasks where a transformer is not available
- Using external modules for processing
- Performing complex manipulations on list attributes
How does it work?
The PythonCaller executes a Python script to manipulate features.
When a specialized task is required, such as custom statistical analysis of an attribute, but FME Workbench does not provide a transformer suited to the task, a Python script can perform specialized and complex operations on a feature's geometry, attributes, and coordinate system.
Note To launch an external editor or IDE for Python script authoring, click External Editor.
Access is provided via the FME Objects Python API.
Note Python is a programming language external to FME. For documentation on creating Python scripts, visit The Python Foundation.
Using Python to perform arbitrary operations on features is a powerful aspect of FME Workbench. However, the logic introduced into a workspace is less visible and can therefore be more difficult to maintain than logic built using FME Workbench’s built-in transformers. It is recommended that other transformers be used when possible instead of Python scripts.
Optional Input Port
This transformer has two modes, depending on whether a connector is attached to the Input port or not:
- Input-driven: When input features are connected, the transformer runs once for each feature it receives in the Input port.
- Run Once: When no input features are connected, the transformer runs one time and outputs a single new feature.
Class Interface
The PythonCaller can interface with a class defined in a Python script.
The supplied script contains a class called FeatureProcessor, which inherits from fme.BaseTransformer. This is a base class that represents the interface expected by the FME infrastructure. See the FME Python module documentation for more information.
The calling sequence on the methods defined in a class depends on which mode the PythonCaller is in. There are two modes - Standard and Group Processing.
Standard Mode
This is the operation mode when no attributes are set in the Group By parameter. Most uses of the PythonCaller will use standard mode processing. In this mode, the PythonCaller will have the following calling sequence on a class:
- __init__() - Called once, whether or not any features are processed.
- input() - Called for each FMEFeature that comes into the input port.
- close() - Called once, after all features are processed (when no more FMEFeatures remain). If no features are processed, the close() method will still be called.
Features that need to continue through the workspace for further processing must be explicitly written out using the pyoutput() method. When using the pyoutput() method, it is recommended to set the output_tag argument to PYOUTPUT.
As of FME 2023.1, bulk mode is enabled by default for the PythonCaller. This allows for significant performance gains when processing large numbers of features. In bulk mode, FME will pass features to the `input()` method which come from a feature table object. The following conditions must be met:
- features passed into the input() method cannot be copied or cached for later use
- features cannot be read or modified after being passed to the pyoutput() method
- Only features passed into the transformer can be output from the transformer. Newly instantiated FMEFeature() objects should not be output from the transformer. Not every feature passed into the transformer needs to be output from the transformer.
- Group processing must not be enabled
Violations will cause undefined behavior. If PythonCaller usage does not meet these requirements, bulk mode should be disabled by altering the has_support_for() method to return False when the support_type argument is equal to fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
When the PythonCaller implementation processes incoming FMEFeatures one at a time, the pyoutput() method is to be called once per incoming FMEFeature in the input() method.
When the PythonCaller implementation requires knowledge of multiple FMEFeatures to process features, the incoming FMEFeatures can be stored in a list, then processed and written out through pyoutput() in the close() method.
The example below calculates the total area of all the features processed and then outputs all the features with a new attribute containing the total area. Note that since features are cached for later use, bulk mode should not be enabled.
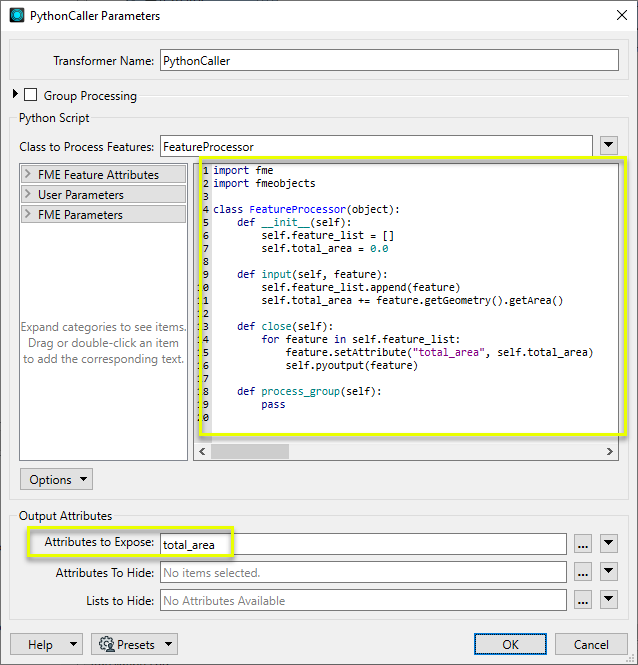
Group Processing Mode
This is the feature processing mode used when one or more attributes are set in the Group By parameter. When using this mode, bulk mode must be disabled by altering the has_support_for() method to return False when the support_type argument is equal to fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
In this mode, the PythonCaller will have the following calling sequence on a class:
- __init__() - Called once, whether or not any features are processed.
- input() - Called for each FMEFeature in a group.
- process_group() - Called after all FMEFeatures in a group have been sent to input(). After this is called and executed, PythonCaller will send the next group of FMEFeatures to input() and then call process_group() again. This is repeated until all groups have been exhausted.
- close() - Called once, after all rounds of input() and process_group() have been called to process all incoming features (when no more FMEFeatures remain). If no features are processed, the close() method will still be called.
In this mode, the class interface will be working on groups of FMEFeatures. The incoming FMEFeatures must be stored in a list class member variable, then processed and written out through pyoutput() in the process_group() method. After processing is complete in process_group(), all class member variables should be cleared for the next round of group by handling. In the next round, FMEFeatures of the next group are passed through input() calls followed again by process_group(). This is repeated until all the groups are exhausted.
The example below calculates the total area of all features grouped by the _shape attribute and then outputs all the features with a new attribute containing the total area for each group:
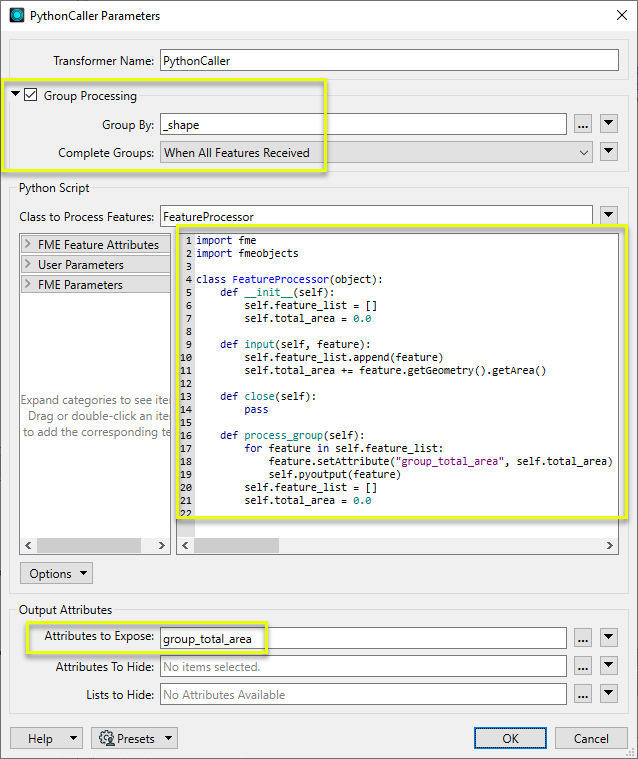
Feature Rejection
Regardless of processing mode, if there are input features that cause operations to fail, they can be sent to the <Rejected> port by using the reject_feature() method defined in the FeatureProcessor class.
Script Editing
A PythonCaller transformer can call scripts that are stored in the transformer itself or scripts that are stored globally for the entire workspace:
- To store a Python script with a specific PythonCaller transformer, use the Python Script parameter in the transformer.
- To store a Python script globally, click the Advanced Workspace Parameter in the Navigator, and double-click Startup Python Script. Storing scripts globally has the advantage of keeping the Python logic centralized, which makes editing and maintenance easier. This is useful when there are multiple PythonCaller transformers throughout the workspace that use the same script. For more information, see Startup and Shutdown Python Scripts in the FME Workbench help.
FME can access .py modules that are stored on the file system, including modules in external Python libraries. Use the Python "import" command to load these modules. FME will search both the standard Python module locations and the workspace location to find the module to be imported.
Configuration
Input Ports
This transformer accepts any feature.
Output Ports
The initiating or new feature, including any modifications made.
Features that have been rejected using the reject_feature() method defined in the FeatureProcessor class. An fme_rejection_code attribute will be added, along with a more descriptive fme_rejection_message attribute which contains more specific details as to the reason for the rejection.
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
|
Group By |
If the Group By parameter is set to a set of attributes, one feature per group will be produced. |
||||
|
Complete Groups |
Select the point in processing at which groups are processed:
There are two typical reasons for using When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations. The second possible reason is potential performance gains. Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains). Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with When All Features Received may be the equivalent and simpler approach. Note Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
|
Class to Process Features |
The name of the Python Class within the script that PythonCaller will use to begin execution. For the above examples, set this parameter to FeatureProcessor. |
|
Script |
The Python script to be executed. When the Python script is stored as the Startup Python Script for the workspace, leave this parameter blank. |
|
Attributes to Expose |
Exposes attributes so they can be used elsewhere in the workspace. Attribute names may be entered directly or provided in the Enter Values for Attributes to Expose dialog accessed via the ellipsis button, where data type may also be specified. For more information on exposed and unexposed attributes, see Understanding Feature Types and Attributes. Used to expose any attributes that are created by the Python script being executed so they can be used by other transformers. |
|
Attributes to Hide |
Hides any attributes that may be removed by the Python script being executed. Other transformers will not be able to use these attributes. |
|
Lists to Hide |
Hides any lists that may be removed by the Python script being executed. Other transformers will not be able to use these lists. Note that if you select to hide a list, your selection will include any list attributes or nested lists. For example, if you select to hide a list called list{} then list{}.attr or list{}.sublist{} will also be hidden. |
|
Feature Output |
Select an output mode regarding the creation of Bulk Mode features:
Bulk Mode may improve performance when processing many features. Note that the transformer becomes Feature Holding, where output features can be held indefinitely when workspaces do not have a natural end, such as having a streaming transformer upstream. Individual Mode prevents these cases. |
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
Feature-Based or Group-Based, conditional on Python script |
|
Feature Holding |
Conditional on Python script or when Feature Output is Bulk Mode. |
| Dependencies |
An FME installation includes a Python version 3.14 interpreter. The FME Objects Python API supports Python 3.10 - 3.14. The Python interpreter used by FME to execute Python scripts is controlled by the Python Compatibility workspace parameter . FME will load the latest available Python interpreter matching that parameter. For more information, see FME Workbench help. If you would like to install a third-party package for use by Python in FME, see Installing Python Packages to FME Form in FME Workbench help. |
| Aliases | |
| History |
FME Online Resources
The FME Community and Support Center Knowledge Base have a wealth of information, including active forums with 35,000+ members and thousands of articles.
Search for all results about the PythonCaller on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.