Merging Similar Datasets
If data sources reside in different locations, you can select them using the advanced browser.
You can add datasets of the same format and with the same schema (data model) to any source dataset you have already defined in your workspace. These datasets will be merged together when you run the translation. For formats that support coverages, you can also add folders and subfolders.
Double-click the dataset name in the Navigator.
In the Edit User Parameter dialog, you can manually enter a path to a file, or multiple files (for example, *.tab). You can also add multiple paths, separated by a comma.
Alternatively, click Select Multiple Folders/Files from the drop-down:
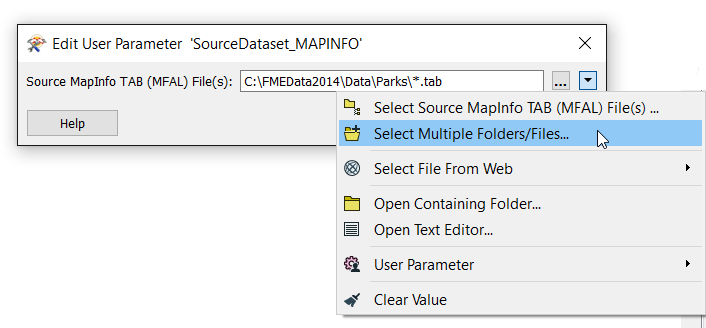
This opens the Select File dialog:
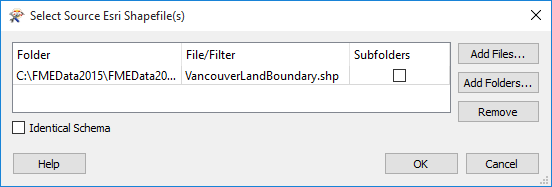
Add Files: Opens the file browser. You can select individual files, or Ctrl + click to select multiple files.
Add Folders: Opens the file browser so you can select entire folders to add to the reader. All files that are in the specified format in those folders will be included.
Remove: Removes the highlighted selection.
Subfolders: If there are subfolders below the initial dataset location, check the box to include them.
Identical Schema Check this box if you know that all the files have the same schema. This is a time-saving function: there will be no difference in the workspace results. If you know the files have the same schema, FME will not have to perform an initial scan of all the files to determine their schema. Instead, FME will take the first file as being representative of the data model.
Click OK to close the dialog, then OK to close Edit Parameter dialog and merge the selected files/folders with the original dataset. To see these results reflected in the Navigator view, float the cursor over the dataset name.