Field Separation
Choose the separator that will divide the fields in the file. By default, this parameter is set to space; however, you can also select one of the following separators:
- , (comma)
- ; (semicolon)
- | (vertical bar)
- tab
By default, each separator is treated as if it separates a different field.
When this parameter is selected, multiple contiguous separators are treated as a single separator.
Some CSV files place quotation marks around all values they contain. When selected, this parameter will strip quotation marks from column values.
If the field or column names of the table are specified in the file, select this value and the names will be extracted from the file. Otherwise, the columns of the table are given default names (for example, col0, col1, ... , colN).
If the column/field names is AFTER the header information instead of BEFORE, then you can set this option. Otherwise, by default, the first line of the file will be used as the column/field names.
Note: This parameter is ignored if File Has Field Names is not selected. If Field Names Follow Header is selected, Lines to Skip should also be set to skip at least 1 row, or the first row will be also be processed as a feature.
Lines to Skip
This indicates the number of lines to skip at the top of the file. By default, 1 line is skipped. Each line skipped is logged to the log file. This is useful if the file contains a header line of field names or other descriptive material (like comments) that should be skipped.
This field indicates the number of footer lines to skip at the bottom of the file. By default, no footer lines are skipped. Each footer line skipped is logged to the log file. This is useful if the file contains a footer line of descriptive material that should be skipped.
Limits the number of lines read into the point cloud.
Component Map Generation
Indicates the number of rows in the file that should be read to generate the automatic mapping of the component map.
The default is 10,000. If this parameter is set to 0, there will be no limit and all rows will be read.
Note: This only affects the component map – it does not affect the reader when the translation is run.
File Preview
Displays a preview of the data, if available.
Point Cloud Component Map
Maps each data column in the Point Cloud XYZ file to a component of the point cloud. This table is automatically populated from the first Point Cloud XYZ file, if one is present. The component map is reset every time a parameter that affects the columns is changed.
If not specified, the point cloud will have one component for each column, with the component name equal to the column name, and where the type is determined by scanning the file.
Using the minimum and maximum x and y parameters, define a bounding box that will be used to filter the input features. Only features that intersect with the bounding box are returned.
If all four coordinates of the search envelope are specified as 0, the search envelope will be disabled.
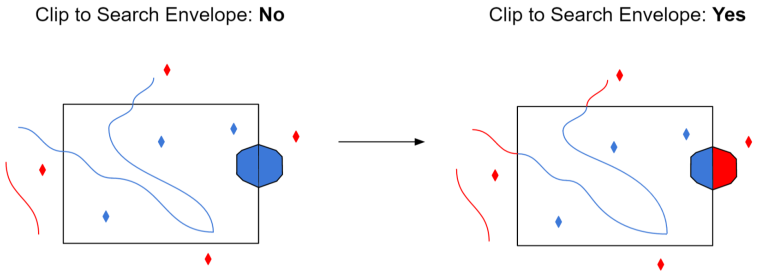
Select this parameter to remove any portions of exported features outside the area of interest.
The illustration below shows the results of the Search Envelope when Clip to Search Envelope is set to No on the left side and Yes on the right side.
- No: Any features that cross the search envelope boundary will be read, including the portion that lies outside of the boundary.
- Yes: Any features that cross the search envelope boundary will be clipped at the boundary, and only the portion that lies inside the boundary will be read. The underlying function for the Clip to Search Envelope function is an intersection; however, when Clip to Search Envelope is set to Yes, a clip is also performed in addition to the intersection.
Advanced
By default, this is set to UTF-8 encoded documents. If this parameter is set to another encoding, the reader will transcode the data to the specified encoding.
Specifies whether string component data may contain separators.
This parameter must be set to Yes if the data contains separators, or the file may be read incorrectly. However, if there are no separators, setting this parameter to No may improve performance.
Schema Attributes
Use this parameter to expose Format Attributes in Workbench when you create a workspace:
- In a dynamic scenario, it means these attributes can be passed to the output dataset at runtime.
- In a non-dynamic scenario where you have multiple feature types, it is convenient to expose additional attributes from one parameter. For example, if you have ten feature types and want to expose the same attribute in each one, it is easier to define it once than it is to set each feature type individually in the workspace.