Data Transformation is FME's ability to manipulate data. The transformation step occurs during the process of format translation. Data is read, transformed, and then written to the new format.
FME Workbench provides many options to control data transformation. Data transformation can be subdivided into two distinct types: Structural Transformation and Content Transformation.
Structural Transformation
This type of transformation is perhaps better called reorganization. It refers to FME's ability to channel data from source to destination in an almost infinite number of arrangements. This includes the ability to merge data, divide data, re-order data, and define custom data structures. Transforming a dataset’s structure requires knowledge of schemas and how to use FME to manipulate them.
Transforming the structure of a dataset is carried out by manipulating its schema.
Content Transformation
This type of transformation is perhaps better called revision. It refers to the ability to alter the substance of a dataset. Manipulating a feature's geometry or attribute values is the best example of how FME can transform content.
Content transformation can take place independently or alongside structural transformation.
Schema Concepts
A schema is the structure of a dataset or, more accurately, a formal definition of a dataset’s structure.
Each dataset has its own unique structure (schema) that includes feature types (layers), permitted geometries, user-defined attributes, and other rules that define or restrict its content.
When a new workspace is created, FME scans all of the source datasets. From this it creates a visual representation of the data’s schema on the left side of the canvas. On the right side, it creates a visual representation of how this schema will be duplicated in the chosen output format.
Here are source and destination schemas as they are represented in Workbench.

Each object on the canvas is a separate Feature Type within a dataset.
The workspace reads from left to right.
At this point, the Reader schema represents what we have (so, FME's view of the source datasets). The Writer schema represents what we want (so, the data required by the user).
By default, the Writer schema is a mirror image of the source; differences only occur when demanded by limitations of the selected destination format. This allows Quick Translation to occur with no further editing of the translation by the user.
Viewing the Schema in FME Workbench
A schema goes beyond what can be seen on the workspace canvas; there are other components in various dialogs that also represent the structure of a dataset.
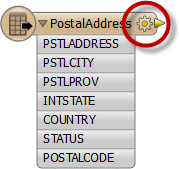
Some parts of the schema relate specifically to a single feature type only. Attributes are one such component. These components are shown in the Properties dialog of a feature type.
The Properties dialog is opened by clicking the Properties button at the right side of the feature type.
The Feature Type Properties dialog contains three or four tabs (depending on the format):
- General: Feature Type name, geometry types, and the name of the parent dataset
- User Attributes: a list of attributes. Each attribute is defined by its name, data type, width, and number of decimal places
- Format Attributes
- Format Parameters
Feature Type Names use format-specific terminology, so instead of Feature Type, the Name Parameters label might be Feature Class, Layer, Sheet, Table, or whatever terminology is specific to the format of data you are writing.
Reader feature type are disabled by default, since source attributes represent the physical schema of the data. If they were changed, the schema would no longer match the Reader dataset. (Note that it is possible to enable reader feature type editing, but this feature is only suggested for use in some advanced scenarios.)
Schema Editing
As noted, initially the Writer schema in a workspace is a mirror image of the source. However, in many cases the user requires the output to have a different data structure.
Schema Editing is the process of altering the destination schema to customize the structure of the output data. One good example is renaming an attribute field in the output. After editing, the source schema still represents ‘what we have’, but the destination schema now truly does represent 'what we want.'
Editable Components
There are a number of edits that can be performed, including, but not limited to, the following.
- Attribute renaming: Attributes on the destination schema can be renamed.
- Attribute type changes: Any attribute on the writer schema can have a change of type; for example, changing a character field to a number field. The Type column for an attribute shows only values that match the permitted types for that data format. For example, an Oracle schema permits attribute types of varchar or clob. MapInfo does not support these data types so they would never appear in a MapInfo schema.
- Feature type renaming: You can change any feature type name.
- Geometry type changes: This field is only available where the format requires a decision on geometry type.
Note: For more information about schema mapping, feature mapping, and attribute mapping, see the FME Workbench help.