Dataset Parameters
This parameter allows you to choose different naming schemes, and the number of feature types generated for the reader.
Feature type name choices:
- From File Name(s): Generates one feature type per source filename.
- From Format Name: Produces only a single feature type containing the format name.
Field Separation
The single character or tab character specified as the separator for the values on a line.
If selected, multiple contiguous delimiters are treated as a single delimiter; otherwise, each delimiter is treated as if it delimits a different field.
Some CSV files place quotation marks around all values they contain. By default, this option is selected and quotation marks will be stripped from column values.
Field Names
If the field or column names of the CSV table are specified in the file, this option ensures that the names will be extracted from the file. Otherwise, the columns of the CSV table are given default names (that is, col0, col1, ... , colN). If the source dataset contains field names, this parameter will be selected by default.
If the column/field names appear AFTER the header information instead of BEFORE, you can select this option. Otherwise, by default, the first line of the file will be used as the column/field names.
Note: This parameter is ignored if Has Field Names is not checked. If Field Names Follow Header is selected, Lines to Skip should also be set to skip at least one row, or the first row will be also be processed as a feature.
Lines to Skip
This parameter sets the number of lines to skip at the top of the file. By default, 0 lines are skipped.
Each line skipped is logged to the log file. This is useful if the CSV file contains a header line of field names or other descriptive material (like comments) that should be skipped.
This parameter sets the number of footer lines to skip at the bottom of the file. By default, 0 footer lines are skipped.
Each footer line skipped is logged to the log file. This is useful if the CSV file contains a footer line of descriptive material that should be skipped.
Schema Generation
If the field structure of the first several rows of a file is representative of the remainder of the file, this option can be set to prevent FME from unnecessarily reading further rows from a potentially large file when determining its schema.
If this is set to 0, there will be no limit and all rows will be read.
Note: Note: This setting only applies to the schema generation; it does not limit the number of rows read when the translation is run.
CSV File Preview
Shows a preview of the input CSV file.
Schema Attributes
This section defines the fields, methods, and directions to use to sort the CSV dataset. If you select this checkbox, features will be produced in the order defined by the parameter values. Once sorting is complete, features will be output from the reader in sorted order.
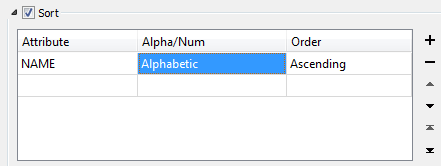
Values: <Field Name>, <Numeric | Alphabetic>, <Ascending | Descending>
This parameter requires information in both Field Names and Filter fields. If not specified, it will filter by the default Filter Matching choice.
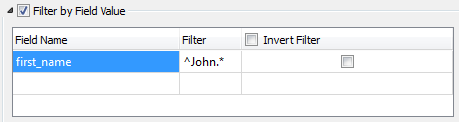
Field Name
Defines which fields of the CSV dataset will be used to filter rows on read.
Filter
Contains the regular expression that will be applied to the selected Field Names. Depending on the value of the Filter Matching parameter, the CSV reader will either ignore rows that match the filter, or only read rows that do match the filter.
Some examples are shown in the table below:
| Example | Regular Expression |
|---|---|
|
Filter by all names beginning with John, where ^ means the beginning of the line. |
^John.* |
|
Filter by surname, include all strings that start with 0 or more of any character, and end with Smith, where $ means the end of the line. |
.*Smith$ |
|
Language/Spelling: For example, if your data contains both English and French, filter by both CANADIAN and CANADIEN, or canadian and canadien. |
CANADI[AE]N canadi[ae]n |
| Filter only empty string values. | ^$ |
Invert Filter
Defines whether the CSV reader will look for the presence or absence of the given regular expression when producing features.
If this parameter is not selected, the CSV reader will only consider rows that contain the specified regular expression when producing features.
If the parameter is selected, the CSV reader will ignore rows that have a field name which matches the regular expression.
When filtering, the CSV reader will only produce features for rows that match all of the specified filters.
Encoding
This specifies the file encoding to use when reading.
| Encodings |
|---|
| UTF-8 |
| UTF-16LE |
| UTF-16BE |
| ANSI |
| BIG5 |
| SJIS |
| CP437 |
| CP708 |
| CP720 |
| CP737 |
| CP775 |
| CP850 |
| CP852 |
| CP855 |
| CP857 |
| CP860 |
| CP861 |
| CP862 |
| CP863 |
| CP864 |
| CP865 |
| CP866 |
| CP869 |
| CP932 |
| CP936 |
| CP950 |
| CP1250 |
| CP1251 |
| CP1252 |
| CP1253 |
| CP1254 |
| CP1255 |
| CP1256 |
| CP1257 |
| CP1258 |
| ISO8859-1 |
| ISO8859-2 |
| ISO8859-3 |
| ISO8859-4 |
| ISO8859-5 |
| ISO8859-6 |
| ISO8859-7 |
| ISO8859-8 |
| ISO8859-9 |
| ISO8859-13 |
| ISO8859-15 |