FME Transformers: 2026.2
Related Transformers
HTTPCaller
Extracts structured data from web page or other HTML sources that are formatted for human readability (screen scraping), using CSS selectors to extract portions of HTML content into feature attributes.
- Extracting content from a web page
How does it work?
The HTMLExtractor lets you define multiple queries to run against incoming HTML content, which can be provided either as an attribute or as a file. The queries are composed of an output attribute name, a CSS Selector which defines what type of tags to extract, and the choice of extracting whole tags, values, text, or HTML attributes.
You may either extract the first matching tag only, or keep multiple results as a list attribute.
The HTMLExtractor is better suited to HTML content than the XML transformers or regular expression searches, due to more lenient parsing and filters that can withstand minor changes to page content.
Examples
In this portion of a workspace, all of the links on a web page will be extracted and output as a list attribute.
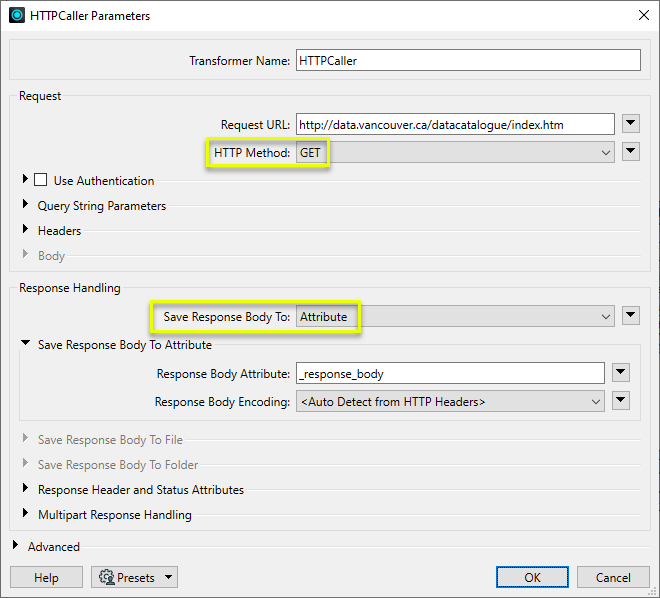
An HTTPCaller retrieves the contents of a web page, using the GET method. The contents of the page are stored as HTML in the _response_body attribute.
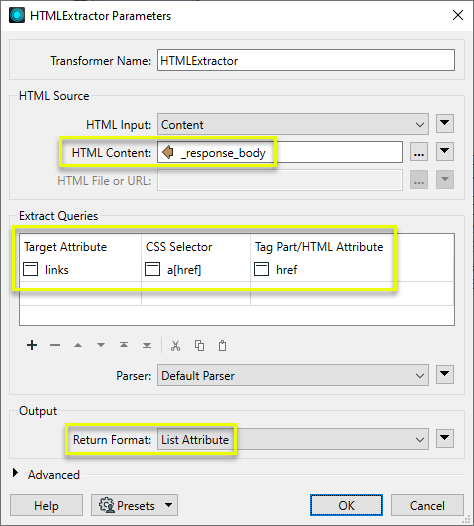
In the HTMLExtractor, the same attribute is set as the HTML source, and a query is constructed to find all links (CSS Selector = a[href]), extract the only the link itself (Tag Part/HTML Attribute = href), and store that in a new attribute called links.
The Return Format is set to List Attribute, and so all matches will be included.
The output will look similar to this:
links{0} = ‘https://www.example.com/page1.html’
links{1} = ‘https://www.example.com/page2.html’
links{2} = ‘https://www.example.com/page3.html’
In this portion of a workspace, an HTTPCaller uses the GET method to retrieve the contents of a web page and store them in the attribute _response_body.

In the HTMLExtractor, a query is constructed to find the div tag with the id “article” (CSS Selector = #article). The contents of that tag will be extracted (Tag Part/HTML Attribute = Value), and output to the new attribute articleText.
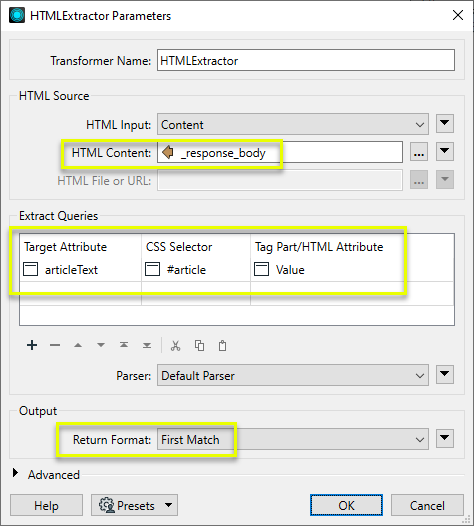
With the Return Format set to First Match, the contents of the first matching div tag encountered will be output as an ordinary (non-list) attribute.
Usage Notes
- Standard CSS selectors are used to create queries. A list of them may be found here: CSS Selector Reference
Configuration
Input Ports
This transformer accepts any feature.
Output Ports
Features with attributes containing the results of Extract Queries..
If an error occurs, the feature will be output via the <Rejected> port, with information about the error contained in the fme_rejection_code and fme_rejection_message attributes.
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
|
HTML Input |
The type of source. Choices include:
|
|
HTML Content |
If HTML Input is set to Content, HTML content can either be specified directly in the HTML Content field, or set to the value of an attribute. |
|
HTML File |
If HTML Input is set to File, the path to an input HTML file can be specified. |
|
Target Attribute |
The name of the attribute that will hold the results of the query. |
|
CSS Selector |
A CSS selector which specifies a tag or set of tags in the HTML document or content. A list of selectors can be found at: |
|
Tag Part/HTML Attribute |
This parameter can be set to
Alternatively, an HTML attribute name (such as “href” or “alt”) can be entered. This will result in the attribute being extracted from the tag. |
|
Parser |
If necessary, select an alternate parsing library. Choices include:
Both parsers should return the same results on well-formatted input, but results may differ if that is not the case. In general, the lxml parser is faster, but the Default Parser is more lenient with input. |
|
Return Format |
If this is set to First Match, the target attributes will contain only the first element found that matches the query. If set to List Attributes, the target attributes will be lists, and will contain all results matching the query. |
|
Verify HTTPS Certificates |
Prior to FME 2022.0, web access through this transformer would automatically disable HTTPS Certificate verification when an SSL Error was received from the server. Now, this behavior must be explicitly enabled or disabled by this parameter. The value of this parameter takes priority over the value of the Verify HTTPS Certificates parameter which might be defined by the Web Connection used with this transformer. |
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
|
|
Feature Holding |
No |
| Dependencies | None |
| Aliases | |
| History | Released: FME 2017.0 |
FME Online Resources
The FME Community and Support Center Knowledge Base have a wealth of information, including active forums with 35,000+ members and thousands of articles.
Search for all results about the HTMLExtractor on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.