The Multi-Reader allows FME to combine several datasets, possibly of different types and different coordinate systems, into one logical input dataset.
Although this capability is most often used to merge data from adjacent mapsheet datasets into a single dataset, it is also used to integrate data from several different sources.
For example, linework from a MicroStation (IGDS) Design file could be formed into polygons using the AreaBuilder transformer, merged with point data and attributes from a Shape file using the PointOnAreaOverlayer, and output to Esri’s Spatial Database Engine (SDE).
Using the Multi-Reader in Workbench
The Multi-Reader is not listed as a "format" in Workbench – it is automatically enabled when you select multiple formats when you create a workspace, or when you modify a workspace to include additional readers.
There are several ways to select multiple formats, but the File Browser and the Advanced Browser are the most common.
File Browser 
The file browser is commonly used to select single datasets but you can also use it to select multiple datasets when they are all stored in the same location.
Advanced Browser 
This option is particularly useful when the source datasets are in different folders. All datasets to be selected must be the same format, and that format must be defined before the advanced browser can be used. The button will not activate until a format is set.
Access the advanced file browser tool from dialog by clicking the Advanced Browser button. It is also available on the Add Reader dialog. For additional information, see Adding Readers to the Workspace in FME Workbench help.
Note: For folder-based datasets (for example, Shapefiles), you are actually selecting feature types, not datasets, but the process is the same.
How the Multi-Reader Works
During an FME run, the Multi-Reader cycles through each individual reader and sends features on to the rest of FME as they are read. When the first reader reaches the end of its data, the second reader is activated. This continues until the Multi-Reader runs out of readers:
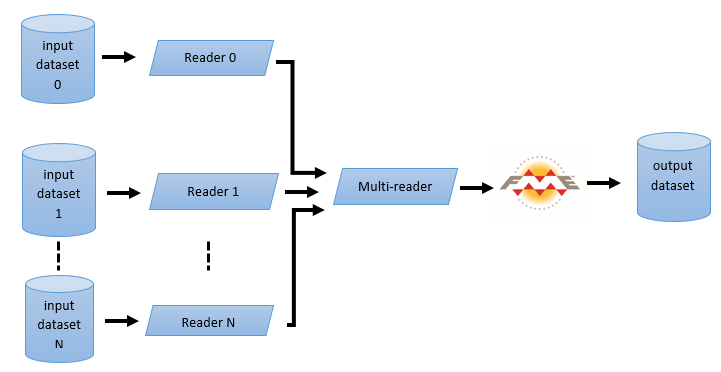
Multi-Reader Process
The Multi-Reader can be configured to operate in two different modes:
- The first mode allows the Multi-Reader to access datasets of different types or datasets of the same type that are located in different folders.
- The second mode allows the Multi-Reader to access multiple datasets of a single type that are located in a common folder. In this mode, individual readers do not need to be identified or configured. Although this mode requires much less configuration in the mapping file for large data merges, there are some limitations to be aware of: the source folder can contain nothing but datasets of the type being read; and the configuration of each individual reader is exactly the same.