FME Flow: 2026.2
Planning for Scalability and Performance
Scale your FME Flow to increase job throughput and optimize job performance.
To increase the ability of FME Flow to run jobs simultaneously, consider any of these approaches:
You can scale FME Flow to support a higher volume of jobs by adding FME Engines on the same machine as the FME Flow Core. A single active Core is all you need to scale processing capacity. The FME Flow Core contains a Software Load Balancer that distributes jobs to the FME Engines. Each FME Engine can process one job at any one time, so if you have ten engines, you can run ten jobs simultaneously. If you have many simultaneous job requests, with jobs consistently in the queue, consider adding engines to your Core machine.
Note Adding engines to the same machine does not reduce the time a single translation takes to run. This time is dependent on the underlying hardware and the design of the workspace. Complex workspaces, big data manipulation, and large datasets take more time to run.
Having multiple engines on the same machine also helps with Job Recovery.
If existing FME Engines are utilizing all system resources to process jobs, you can add FME Engines on a separate machine or access Remote Engines Services. Either approach allows you to use the system resources of multiple machines, which allows additional concurrent jobs to be run.
A fault tolerant architecture provides for multiple, stand-alone FME Flow installations. In addition to providing fault tolerance, this configuration distributes jobs between FME Flows via a third-party load balancer.
Using the following approaches, you can provide flexibility for running jobs in close physical proximity to the data they read and write:
- Adding FME Engines on a Separate Machine: This approach requires the engine machines to be in the same network, and in the same data center or geographically close.
- Remote Engines Services: This approach works well when you want to access FME Engines on servers outside of your network on accessible endpoints or in a Cloud service, while maintaining your primary FME Flow installation behind a firewall. It can also be deployed within a network.
To ensure each job is run by the intended engine, you must use either approach in combination with Queue Control.
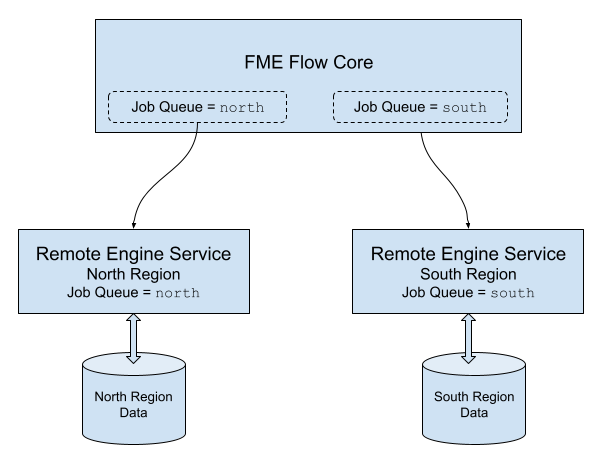
In this Remote Engines Service example, consider two data sources - one located in a northern region, and another located in a southern region. To run jobs efficiently, it makes sense to access remote engines in both regions. Jobs that are run on queue north access data in the northern data store. These jobs are routed to remote engines located in the northern region. Likewise, jobs that are run on queue south access data in the southern data store. These jobs are routed to remote engines located in the southern region.
To exercise a finer level of control over how jobs are processed, consider the following approaches:
Queue Control manages or spreads the work load of engines running workspaces. In a distributed environment, you may wish to run small jobs on certain engines, and larger jobs on other engines.
Or, you may have a mix of OS platforms on which certain FME formats can and cannot be run. For instance, consider an FME Flow on a Linux OS. Linux cannot run some formats that may be required by your business. So, it may be necessary to have a Windows OS configured with an additional FME Flow Engine.
Queues are also used when Adding FME Engines on a Separate Machine or with Remote Engines Services, to route jobs to engines that are located in close physical proximity to the data they read and write.
You can set engines to process certain jobs based on the queue of the transformation request.
FME Flow allows you to set job priority using the Priority directive of a queue. Jobs in higher-priority queues may execute before jobs in lower-priority queues.