FME Transformers: 2026.2
Related Transformers
DatabaseJoiner
DatabaseQuerier
FeatureJoiner
FeatureMerger
ListBasedFeatureMerger
Matcher
SQLCreator
SQLExecutor
Creates SQLite database tables from incoming features, executes SQL queries against them, and outputs the results as features.
Typical Uses
- Performing SQL queries on any features, whether or not they originate from a SQL supporting format.
- Executing complex queries and joins without multiple transformers
How does it work?
The InlineQuerier creates a temporary SQLite database, and creates a table for each input object that is connected to it. In the parameters dialog, you may create any number of SQL queries that use these tables. Each query defined has an output port paired with it, and the query results are output as features.
Input table definitions can be easily created by connecting to the Connect Input port. They can also be defined by importing the schema of any feature type in the workspace, whether connected or not (though the table will not be populated unless the feature type is connected). Any number of tables may be created.
SQL queries can involve any and all tables and columns defined in the input. In particular, multi-way joins can be executed, advanced SQL operations involving nested Select statements and advanced predicates can be used, and the input tables can be used by multiple queries.
See the SQLite documentation for a detailed reference on the SQL Select statement syntax that is supported.
Examples
In this example, we will use an InlineQuerier to perform a SQL join between Park polygons in a shapefile and attributes in a CSV text file. Both sets of features have a common key - the ParkId attribute.
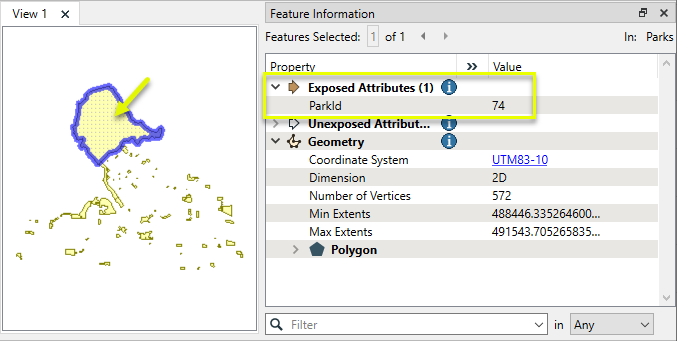
When the InlineQuerier is first placed in the workspace, it has no Input or Output ports.
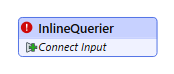
After adding both dataset readers, we connect each one to Connect Input. Table definitions and Input ports are created.
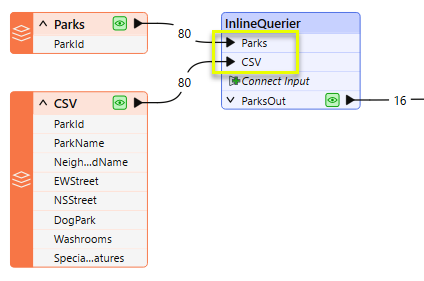
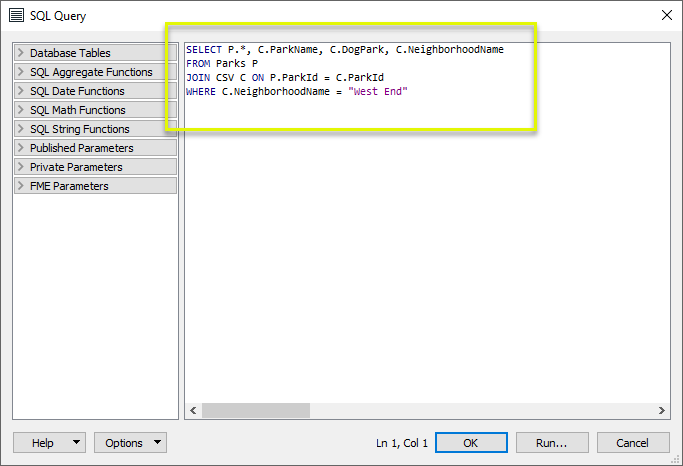
In the parameters dialog, we add an Output Port called ParksOut, and construct a SQL query that will provide the features to be output.
This query joins the CSV features to Parks via their common key, and selects three new attributes to be added to the Park features (ParkName, DogPark, and NeighborhoodName). As well, only parks in the West End neighborhood will be output.
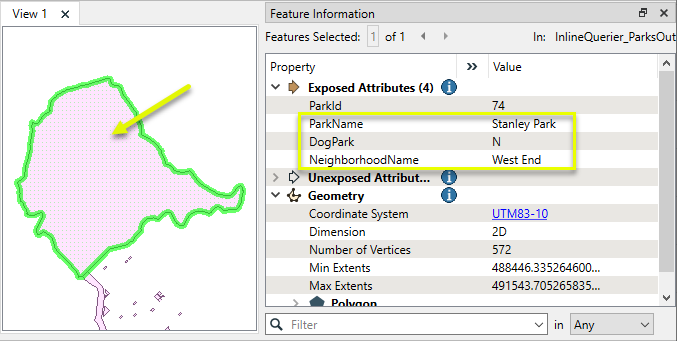
For each Park feature, the query is executed and new attributes attached. The features are output via the ParksOut port we defined, associated with the SQL query.
Usage Notes
- Consider using the InlineQuerier to replace multiple FeatureMergers. The InlineQuerier allows its input data to be reused multiple times in a single transformer, whereas if multiple joins are to be done with a FeatureMerger, multiple FeatureMergers must be employed and copies of the features sent to each. On the other hand, there is some overhead for the InlineQuerier to load the underlying SQLite database. Using a single InlineQuerier instead of several FeatureMergers also simplifies the workspace.
Unless only a single FeatureMerger is needed in a workflow, the InlineQuerier may be a better choice. Older workspaces with multiple cascading FeatureMergers may experience a performance improvement by replacing the FeatureMergers with a single properly configured InlineQuerier. - If all the data to be queried already resides in a SQL-capable data source, consider using the SQLExecutor or SQLCreator instead, as queries will be more efficient when performed by the source database.
- If the query is a simple join between features and a database source, and the key(s) are indexed in the database, consider using a DatabaseJoiner for more efficient processing.
Choosing a Feature Joining Method
Many transformers can perform data joining based on matching attributes, expressions and/or geometries. When choosing one for a specific joining task, considerations include the complexity of the join, data format, indexing, conflict handling, and desired results. Some transformers use SQL syntax, and some access external databases directly. They may or may not support list attribute reading and creation.
Generally, choosing the one that is most specific to the task you need to accomplish will provide the optimal performance results. If there is more than one way to do it (which is frequently the case), time spent on performance testing alternate methods may be worthwhile. Performance may vary greatly depending on the existence of key indexes when reading external tables (as opposed to features already in the workspace).
|
Transformer |
Match By |
Uses SQL Statements |
Can Create List |
Input Type |
Notable |
Description |
|---|---|---|---|---|---|---|
| FeatureJoiner | Attributes | No | No | Features |
|
Joins features by combining the attributes and/or geometry of features based on common key attribute values. Performs Left, Inner, and Full joins. |
| FeatureMerger | Attributes | No | Yes | Features |
|
Merges the attributes and/or geometries of one set of features onto another set of features, based on matching key attribute values and expressions.
 |
| ListBasedFeatureMerger | List Attribute to Single Attribute | No | Yes | Features |
|
Merges the attributes and/or geometries of one set of features onto another set of features, based on matching list attribute values with key attribute values and expressions. |
| InlineQuerier | SQL query | Yes | No | Features |
|
Creates SQLite database tables from incoming features, executes SQL queries against them, and outputs the results as features. |
|
SQL or Cypher query |
Yes |
No |
External DB |
|
Executes queries against a database, producing query results and/or schema. |
|
| SQLCreator | SQL query | Yes | No | External DB |
|
Generates FME features and/or schemas from the results of a SQL query executed against a database. One FME feature is created for each row of the results of the SQL query.
|
| SQLExecutor | SQL query | Yes | No | External DB |
|
Executes SQL queries against a database.
|
| DatabaseJoiner | Attributes | No | Yes | External DB and Features |
|
Joins attributes from an external table to features already in a workspace, based on a common key or keys.
|
| Matcher | Geometry and/or Attributes | No | Yes | Features |
|
Detects features that are matches of each other. Features are declared to match when they have matching geometry, matching attribute values, or both. A list of attributes which must differ between the features may also be specified.
|


Configuration
Input Ports
Input ports are variable, and will appear as the user connects input features, imports table definitions, or manually defines them.
Output Ports
Output ports are variable, and will appear as the user creates pairs of SQL queries with named outputs in the parameters dialog.
Parameters
The InlineQuerier requires definition of one or more Tables, which will become input ports to the transformer.
The simplest way to define a table is to connect features to the Connect Input port.
The Import… button will add a definition from the source feature types in the workspace.
You may also manually define Tables and Columns.
|
Table |
The name of the table. |
|
Query Columns |
The name(s) of columns to be defined, separated by commas. |
Tip To optimize performance, define as few columns as necessary.
When adding columns you can specify the type as geometry. This will cause the transformer to write a geometry column with that name. The name can then be used to spatially query in the Outputs table.
At runtime, the transformer will build an index for each of the columns before any of the queries are processed.
In addition to the columns defined, a special fme_feature_content column is implicitly defined on every table, and at runtime this column can be considered to contain the entire contents of the FME feature that entered through the table’s port. Because of this, only attributes that will be used in filtering or joining should be defined for the table – any additional attributes (as well as feature geometry) can be put onto the resulting output features by selecting the fme_feature_content column.
Note Features routed to input ports should have attributes on them which match the schema defined for the input port table. If they do not, null values will be inserted in place of missing attributes for the columns defined for the input table. Use a direct connection to the Connect Input port (or the Import... button) to ensure matching.
Alternatively, an upstream AttributeRenamer or NullAttributeMapper can be used to ensure that attribute values are present for defined columns.
Alternatively, an upstream AttributeRenamer or NullAttributeMapper can be used to ensure that attribute values are present for defined columns.
Note Table Contents: the Tables defined for the input ports require Columns for each attribute referenced in a query.
They do not have to contain additional attributes. In most cases, a SELECT * type of query will be performed, which will include all of the attributes and source geometry from the original feature, contained in the special fme_feature_content column.
Removing unused columns may optimize performance.
They do not have to contain additional attributes. In most cases, a SELECT * type of query will be performed, which will include all of the attributes and source geometry from the original feature, contained in the special fme_feature_content column.
Removing unused columns may optimize performance.
|
Output Port |
Enter a name for each desired output port. Each output port is assigned a SQL query. |
|
SQL Query |
The SQL query that will produce features for the output port. An editor is available to construct the queries, with drag and drop access to tables, columns, and user parameters which can be used within the query. If the result of a query includes a fme_feature_content attribute (either explicitly or through the use of a SELECT *), then the content of the original feature will be included on the output feature. Note that all fme_feature_content attributes take the form of In the event where the query joins multiple tables with multiple values of fme_feature_content, the attributes of the resulting features will be merged in the order in which the fme_feature_content values are encountered in the query. If the original features had attributes with the same names, then the first fme_feature_content found in the resulting row will have its feature attributes on the output feature, and subsequent fme_feature_content will have their duplicate feature attributes ignored during the merging. (If this is not desired, you could use an AttributeRenamer prior to the InlineQuerier to ensure unique attribute names in the input streams.) |
|
Geometry |
First Feature - the resulting merged feature will, by default, have the geometry from the first source feature encountered. Aggregate of all features - the resulting merged feature will contain an aggregate geometry of all of the input features, in the order in which their respective fme_feature_content values were encountered. Coordinate System of Output Features The coordinate system on the output feature will be:
Otherwise it will be left unset. |
|
Generate |
The Generate button will create one output port with a default Select * query for each input table. |
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
Not Applicable |
|
Feature Holding |
Not Applicable |
| Dependencies | None |
| Aliases | |
| History |
FME Online Resources
The FME Community and Support Center Knowledge Base have a wealth of information, including active forums with 35,000+ members and thousands of articles.
Search for all results about the InlineQuerier on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.