FME Transformers: 2026.2
Related Transformers
DatabaseDeleter
DatabaseUpdater
FeatureJoiner
FeatureMerger
InlineQuerier
ListBasedFeatureMerger
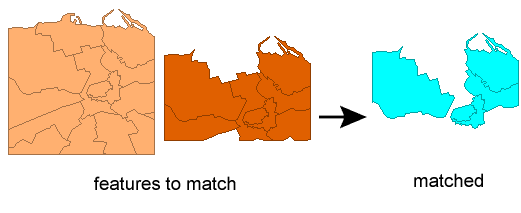
Matcher
SQLCreator
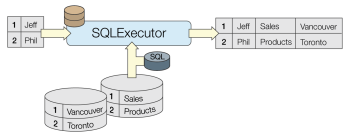
SQLExecutor
Joins attributes from an external table to features already in a workspace, based on a common key or keys.

Typical Uses
- Joining attributes from an external database table to features already in a workspace
How does it work?
The DatabaseJoiner queries an external table to retrieve attributes associated with a feature. One or more feature attributes (primary keys) are matched to one or more columns (foreign keys) in a table in the database, and the values from the matching table row(s) are added to the feature as attributes.
A number of matching methods (Cardinality) are available - Match All (1:M), First (1:0..1+), Exactly One (1:1), or Zero or One (1:0..1). Features that do not fulfill the matching conditions are output via the <Rejected> port.
The _matched_records attribute specifies how many records in the database the feature matched to. Multiple matches can create multiple features or add a list attribute to a single feature.
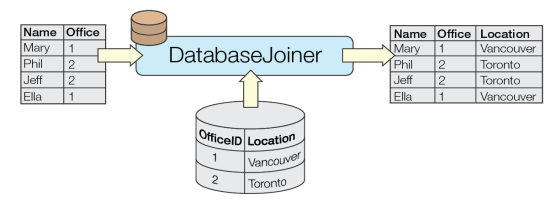
The DatabaseJoiner allows simple join relationships based on multiple attribute keys and requires no knowledge of SQL – this is often very effective for simple lookup tables.
Examples
In this example, we want to retrieve attributes from a table in a PostGIS database, and add those attributes to park polygons stored in a shapefile. The parks have an ID number which will be used to do the joining.
The features are routed into a DatabaseJoiner, where we will retrieve the rest of the attributes we want.
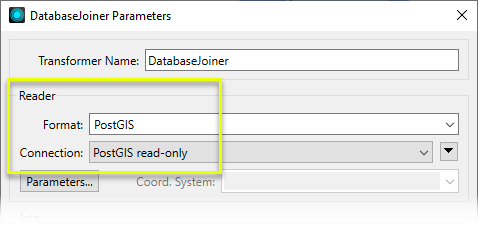
In the parameters dialog, the first step is to define the external database - much like configuring a regular database format reader.
With the database connection made, we now select the desired table (public.Parks) via the browse button next to Table. This will load a list of available table to choose from. We then choose the attribute from both the incoming parks (Feature Attribute) and joined table (Table Field) to join on. In both cases, the attribute is called ParkId.
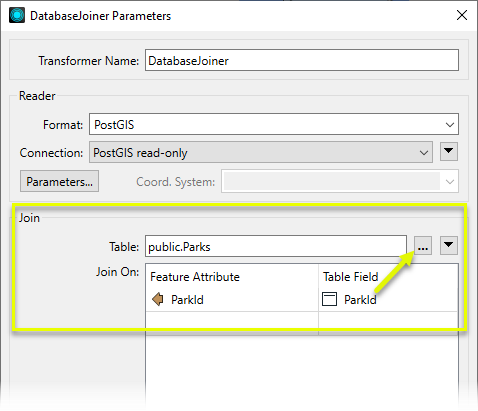
Fields to Add determines which attributes from the external database table are added to the Park features. We Select All of them.
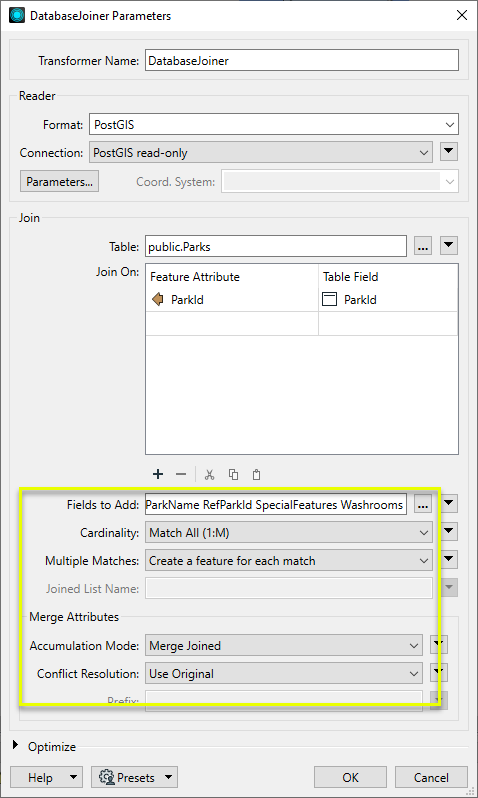
The default values for Cardinality, Multiple Matches, and attribute merging will provide the results we want.
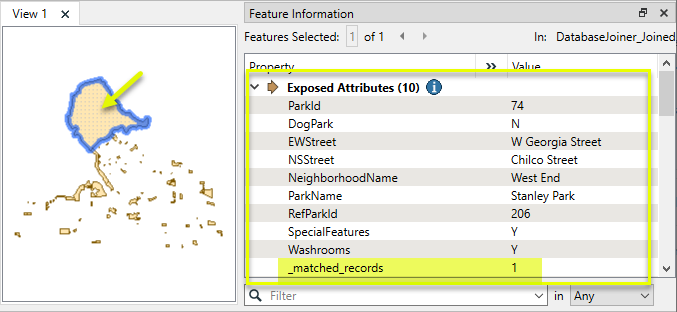
The output features from the Joined port now have additional attributes that were retrieved from the external database table. Note that the _matched_records attribute shows how many matches were encountered - in the case, one.
Usage Notes
- For optimal performance, ensure that the keys (attributes to be joined on) are indexed in the database. If keys are indexed, the DatabaseJoiner can be considerably more efficient than other joining transformers.
- To join two feature streams that are already in a workspace, consider using the FeatureMerger, which also provides geometry merging options.
- If all data resides in a SQL-capable source, consider using the SQLCreator or SQLExecutor, which can also execute more complex join queries which are processed in the source database. For a simple join, the DatabaseJoiner may be the most efficient approach.
- The DatabaseJoiner does not require knowledge of SQL.
- To perform SQL join queries (simple or complex) on non-SQL data sources, consider using the InlineQuerier.
Choosing a Feature Joining Method
Many transformers can perform data joining based on matching attributes, expressions and/or geometries. When choosing one for a specific joining task, considerations include the complexity of the join, data format, indexing, conflict handling, and desired results. Some transformers use SQL syntax, and some access external databases directly. They may or may not support list attribute reading and creation.
Generally, choosing the one that is most specific to the task you need to accomplish will provide the optimal performance results. If there is more than one way to do it (which is frequently the case), time spent on performance testing alternate methods may be worthwhile. Performance may vary greatly depending on the existence of key indexes when reading external tables (as opposed to features already in the workspace).
|
Transformer |
Match By |
Uses SQL Statements |
Can Create List |
Input Type |
Notable |
Description |
|---|---|---|---|---|---|---|
| FeatureJoiner | Attributes | No | No | Features |
|
Joins features by combining the attributes and/or geometry of features based on common key attribute values. Performs Left, Inner, and Full joins. |
| FeatureMerger | Attributes | No | Yes | Features |
|
Merges the attributes and/or geometries of one set of features onto another set of features, based on matching key attribute values and expressions.
 |
| ListBasedFeatureMerger | List Attribute to Single Attribute | No | Yes | Features |
|
Merges the attributes and/or geometries of one set of features onto another set of features, based on matching list attribute values with key attribute values and expressions. |
| InlineQuerier | SQL query | Yes | No | Features |
|
Creates SQLite database tables from incoming features, executes SQL queries against them, and outputs the results as features. |
|
SQL or Cypher query |
Yes |
No |
External DB |
|
Executes queries against a database, producing query results and/or schema. |
|
| SQLCreator | SQL query | Yes | No | External DB |
|
Generates FME features and/or schemas from the results of a SQL query executed against a database. One FME feature is created for each row of the results of the SQL query.
|
| SQLExecutor | SQL query | Yes | No | External DB |
|
Executes SQL queries against a database.
|
| DatabaseJoiner | Attributes | No | Yes | External DB and Features |
|
Joins attributes from an external table to features already in a workspace, based on a common key or keys.
|
| Matcher | Geometry and/or Attributes | No | Yes | Features |
|
Detects features that are matches of each other. Features are declared to match when they have matching geometry, matching attribute values, or both. A list of attributes which must differ between the features may also be specified.
|

Configuration
Input Ports
Features to be joined with attributes from an external table.
Output Ports
Features that successfully matched.
Features that had no matches.
If Cardinality is set to Must Match Exactly One or Must Match Zero or One, then features that do not meet the criteria are rejected.
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
The DatabaseJoiner is a very powerful transformer with many performance-related settings.
|
Format |
Select the format of the external dataset, or allow it to be guessed from the dataset selected. |
|
Dataset or Connection |
Select the dataset to be read. Depending upon the format, this may be a file, folder, or database connection. |
|
Parameters |
Access reader parameters specific to the chosen reader and dataset. |
|
Table |
Specify the table to join. Click the Browse button to select the table from a list. Note that you can only select this after you have completely specified the reader format, dataset, and format-specific parameters. |
||||||||
|
Join On |
Select the attribute(s) from the incoming feature and their corresponding table field(s) that will be used to find matches. Matches are made when the values of all the attributes equal the values of their corresponding table fields. There is one row for each attribute and column pair in the table entry widget. You can add more pairs by clicking the plus (+) button located to the right of the table. Similarly, you can remove pairs by pressing the minus (-) button. A minimum of one pair must be specified for the join to work. Select attributes from a drop-down list in the Feature Attributes column. (You can type directly in the corresponding table fields or select from a list by clicking the Browse button.) For the Browse button to list available table fields, all the information needed to read from the table needs to be specified. Join Row Tools:
These tools may be used to Add, Delete, Cut, Copy, and Paste rows. |
||||||||
|
Fields to Add |
Specify a list of fields from the matching table rows to join onto the incoming feature. To select the fields from a list, click the Browse button. A dialog showing the list of possible fields will appear. Place a check next to each field you wish to add, and click OK. If no fields are specified, all the fields from the matching rows will be added. |
||||||||
|
Cardinality |
Indicate the type of relationship between the database rows and each feature. This will describe how many rows will match to each feature and what action the DatabaseJoiner will take if the expected number is not found. Choices include:
The Must Match rules are very strict. When in doubt, use Match First or Match All. |
||||||||
|
Multiple Matches |
Specify how results of multiple matches will be given. Create a feature for each match: Each row matched is added to a copy of the incoming feature. In this scenario, for each feature in, there will be matched features out. If there are no matches, the feature exits the Unjoined output port. Add fields on a list attribute: Each row matched is added to a list attribute on the feature. If there are no matches, the feature exits the Unjoined output port. |
||||||||
|
Joined List Name |
The name of the list attribute to append multiple matches. Note List attributes are not accessible from the output schema in FME Workbench until they are exposed with an AttributeExposer or processed with a transformer that operates on them, such as a ListExploder or ListConcatenator.
|

|
Accumulation Mode |
If Merge Joined is chosen, attributes from the feature and table will be merged, and in case of conflicts the value specified in the Conflict Resolution parameter will be used. If Prefix Joined is chosen, then all incoming attributes will be presented with a prefix set in the Prefix parameter. |
|
Conflict Resolution |
This parameter is enabled when Accumulation Mode is set to Merge Joined. Use Original and Use Joined will give priority to original and incoming attributes respectively in case of attribute conflicts. |
|
Prefix |
The specified value is used as a prefix for incoming attributes when Accumulation Mode is Prefix Joined. |
Tip
|
Prefetch Query |
For Database formats only. For formats that support SQL, the DatabaseJoiner cache can be preloaded (that is, filled with a specific set of data before matching takes place) by issuing a prefetch query. This prefetch query can select an entire table or selected parts of a table most likely to be matched by the feature attributes. For example, a number of FME features of type "highways" require a database match. The database table (myrecords) has a field (record_type) with a number of values; road, highway, avenue, street. The FME features will only ever be matched to where record_type=highway so the overall join process would be much more efficient if the following prefetch was issued: SELECT * from myrecords where record_type = 'highway' Note Unless the prefetch query is exhaustive, cache size limits apply. See Prefetch Exhaustive to learn what constitutes an exhaustive prefetch query
|
|
Prefetch Exhaustive |
For Database formats only. A prefetch query which is known to retrieve all possible matches is called an exhaustive query. In this case the database is never further consulted for a match. When a match cannot be found within the cached results of an exhaustive query, it is assumed that no match exists. If Prefetch Exhaustive is set to Yes, this indicates whether a prefetch is exhaustive (and the user doesn’t want to query the database any further). Even when it is set to No, however, any prefetch query is assumed to be exhaustive when it does not contain a WHERE clause, and is of the form: SELECT * from TableName Note When FME considers a prefetch query to be exhaustive, the cache size limit will be ignored. This is because the cache must contain all results from the query.
|
|
Cache Size |
For Database formats only. Specify the number of rows to cache locally if you do not want to accept the default of 5000. You can optionally specify a SQL query to preload the cache. Note that cache size is ignored if the prefetch query is exhaustive. |
|
Trim Key Fields |
Appears for character fields. Engaging trimming of key fields may significantly reduce performance and should only be done if key column values in the database are known to contain trailing spaces. It has no effect if an exhaustive prefetch query is used (see above for an explanation of Prefetch Exhaustive). Note This parameter is included for backwards compatibility and most users will have no need to use it. The parameter can only be accessed using the pane of the FME Workbench.
|
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
|
|
Feature Holding |
No |
| Dependencies | Format-dependent - may require third-party drivers for some formats |
| Aliases | Joiner |
| History |
FME Online Resources
The FME Community and Support Center Knowledge Base have a wealth of information, including active forums with 35,000+ members and thousands of articles.
Search for all results about the DatabaseJoiner on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.