FME Transformers: 2025.1
Simplifies, smoothes, measures, or fits geometry according to a variety of algorithms.
Typical Uses
- Simplifying geometry for use at different scales
- Simplifying geometry to optimize storage or processing time
- Smoothing jagged lines
How does it work?
The Generalizer receives features with vector geometry and applies a selected algorithm.
There are four types available, and different algorithms may be more suitable for particular purposes or datasets:
- Generalize: These algorithms simplify features by removing vertices.
Douglas and Douglas with Arc Fitting - Remove vertices that deviate little.
Thin and Thin No Point - Remove vertices that are close together.
Deveau - Remove vertices with less effect on shape.
Wang - Remove insignificant bends.
-
Smooth: These algorithms move vertices to produce smoother geometry.
- McMaster and McMaster Weighted Distance - Move vertices based on their neighbors.
- NURBfit - Fit smooth curves to the geometry and stroke them.
- Fillet - Round sharp corners.
- Measure: This algorithm finds inflection points.
- Inflection Points - Produce points to measure sinuosity.
- Fit: This algorithm produces a two-point line based on vertices.
- Orthogonal Distance Regression - Find an optimal path through vertices.
Areas that have common boundaries may have those shared portions optionally preserved.
Generalizing Algorithms
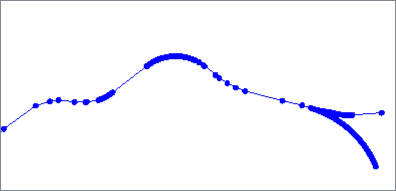
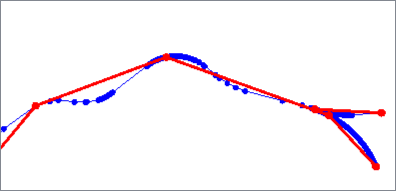
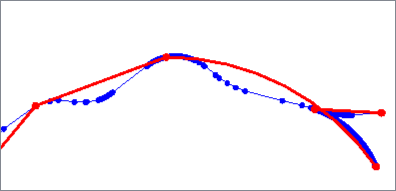
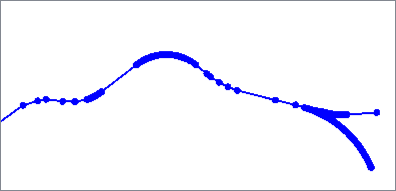
The Douglas algorithm removes vertices that deviate less than a specified distance from a line connecting vertices within the geometry.
The vertices are evaluated by initially connecting the first and last point, identifying vertices to be kept, then recursively evaluating shorter and shorter segments until only points identified as kept remain.
Critical points are retained and vertices are not moved. When applied to a polygon, the first point will always be kept.
Douglas with Arc Fitting also fits arcs to the geometry where possible to further reduce the number of vertices. Output features may have path geometry.
Based on the Ramer–Douglas–Peucker algorithm.
|
Input Feature |
|
|
Douglas |
|
|
Douglas With Arc Fitting |
|
Algorithm Parameters
|
Generalization Tolerance |
Maximum deviation in ground units. Vertices offset less than this distance are discarded. |
The Thin algorithm removes vertices that are less than a specified distance from an adjacent vertex. First and last points are not removed.
If a feature’s entire length is less than the Generalization Tolerance, it is replaced either by a point at the last coordinate (Thin) or a two-point line connecting the first and last vertices (Thin No Point).
|
Input Feature |
|
|
Thinned |
|
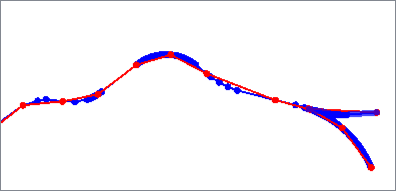
Algorithm Parameters
|
Generalization Tolerance |
Maximum distance between vertices in ground units. |
The Deveau algorithm removes vertices that contribute less to the overall shape of the feature. It uses rectangular bands of tolerance that move along the feature to determine which vertices are discarded, also evaluating angles to identify significant features to keep.
Smoothness can be increased to further reduce vertices.
Output features are 2D and any measures are removed.
Based on the Deveau algorithm.
|
Input Feature |
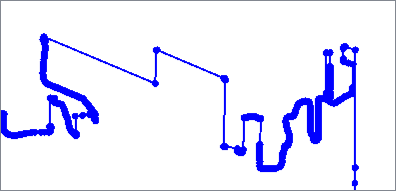
|
|
Deveau Minimum Smoothness (1) |
|
|
Deveau Maximum Smoothness (30) |
|
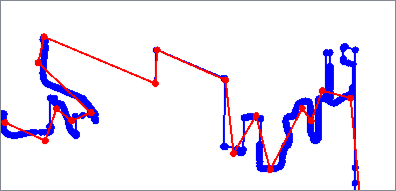
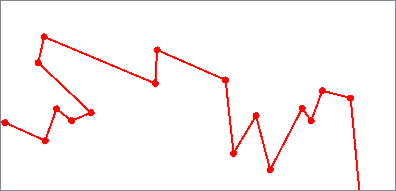
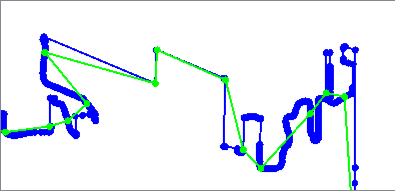
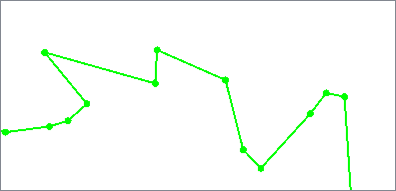
Algorithm Parameters
|
Generalization Tolerance |
Width of the tolerance band in ground units. A wider band removes more vertices. Corresponds to Deveau’s TOL variable. |
|
Smoothness Factor |
An integer ranging from 1 to 30. Higher smoothness values remove more vertices. Default: 1 Corresponds to Deveau’s NW variable. |
|
Sharpness Angle |
Spikes with a vertex angle less than this value and height and width greater than the Generalization Tolerance are considered significant features and will not be blunted. Accepted values: 0 to 180.0 degrees Default: 110 Corresponds to Deveau’s ANG variable. |
The Wang algorithm removes insignificant bends by iteratively evaluating them against a reference circle.
For each bend, a value is calculated - 75% of the area of a circle with circumference equal to the bend’s perimeter. If this value is less than the area of the reference circle, the bend is generalized.
Based on the Wang-Müller algorithm.
See also: SherbendGeneralizer
| Input Features |

|
|
Wang |
|
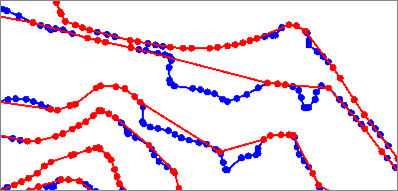

Algorithm Parameters
|
Generalization Tolerance |
Diameter of the reference circle. |
Smoothing Algorithms
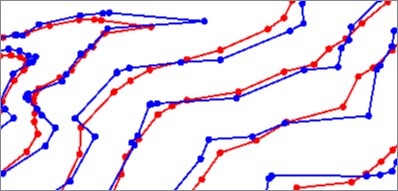
The McMaster algorithms smooth lines by adjusting vertex position based on neighboring vertices.
The coordinates of a specified number of neighbors on both sides of the vertex are averaged to produce a new location. The vertex is moved a specified percentage of the distance between the new and original locations, with the default of 50 being halfway between. Lower percentages move nearer the new location and higher percentages move nearer the original.
When using weighted distance, inverse distance weighting is applied before averaging. Weight is the reciprocal of the distance from the vertex being smoothed multiplied by the Weighting Power value. Neighbors that are further away have less effect than those nearby.
The overall effect using either method is to pull vertices towards their neighbors, smoothing the line.
Geometry is not simplified - output features have the same number of vertices as input.
The first and last vertices of features are handled according to the Number of Neighbors (N):
- Lines: The first N and last N vertices are not smoothed.
- Areas: All vertices are smoothed.
- Adjacent Areas: When Preserve Shared Boundaries is Yes, collinear portions of their boundaries will be smoothed together. Unshared portions are smoothed as lines (first N and last N vertices are not smoothed).
Based on McMaster's Sliding Averaging Algorithm and McMaster's Distance-Weighting Algorithm.
|
Input Features |

|
|
McMaster |
|
|
McMaster Weighted Distance |
|


Algorithm Parameters
|
Number of Neighbors |
The number of points on either side of the vertex to include in the averaged location. Default: 2 |
|
Displacement Percentage |
The final position of the vertex as a percentage of the distance between the averaged location and original location. Default: 50 |
|
Weighting Power |
When using McMaster Weighted Distance, a value to multiply the vertex distance by. Default: 1.0 |
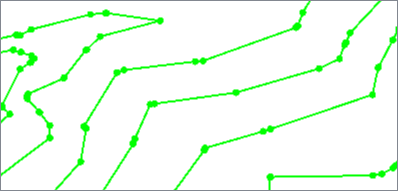
The NURBfit algorithm fits B-Spline curves to the input features and strokes the results to output linear geometry.
Spline shapes are determined by the polynomial degree and desired output segment length. Higher degrees produce smoother curves. Segment Length is measured in ground units and controls the density of vertices on the output feature.
See Non-uniform rational B-spline
|
Input Features |
|
|
NURBfit |
|


Algorithm Parameters
|
Degree of Basis Polynomial |
Degree of the polynomial used to approximate the curve. The higher the degree, the smoother the line. Accepted values:Integers >= 2 Default: 2 |
|
Segment Length |
Output segment length in ground units. If zero (0), the segment length will be calculated so that the output feature has 10x the number of vertices as the input feature. Accepted values: Numbers >= 0 Default: 0 |
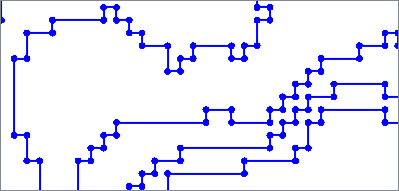
The Fillet algorithm replaces corners with arcs.
If an arc of the specified radius does not fit in a corner, it is output unchanged.
|
Input Features |
|
|
Fillet |
|
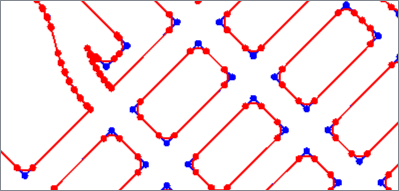
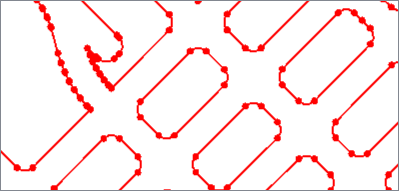
Algorithm Parameters
|
Fillet Radius |
Arc radius in ground units. Accepted values: Numbers > 0 |
Measuring Algorithm
The Inflection Points algorithm identifies a feature’s inflection points and outputs them as aggregate multi-point geometry.
The calculation incorporates neighboring vertices, which can be adjusted. Zero (0) means no neighbors are considered. Increasing the number of neighbors smooths the line and may result in fewer inflection points.
See Sinuosity and Inflection Points.
|
Input Feature |
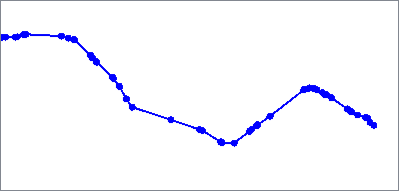
|
|
Inflection Points |
|
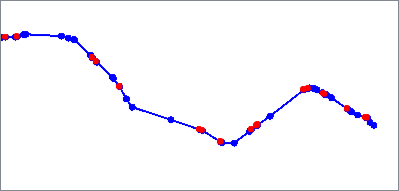

Algorithm Parameters
|
Number of Neighbors |
The number of adjacent vertices to consider in inflection point calculation. Accepted values: Integers >= 0 Default: 2 |
Fitting Algorithm
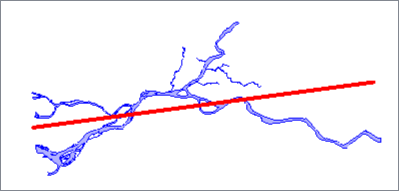
The Orthogonal Distance Regression algorithm replaces the feature's geometry with a two-point line that minimizes the orthogonal distance between it and the original geometry's vertices.
Orthogonal distance is the shortest perpendicular distance between a point and a line.
|
Input Feature |
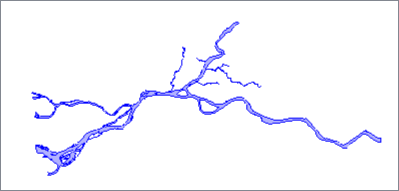
|
|
Orthogonal Distance Regression |
|
Algorithm Parameters
This algorithm has no parameters.
Usage Notes
- To maintain topologies that involve other features while generalizing, consider using the SherbendGeneralizer.
- The Densifier may be useful in cases where generalization is too aggressive in portions of the data.
Configuration
Input Ports
Features to be generalized.
Output Ports
Features generalized as specified in parameters. Attributes are kept.
Features with invalid or otherwise non-generalizable geometry are output here, as are any features that receive non-numeric values for any numeric parameters.
Rejected features will have an fme_rejection_code attribute with one of the following values:
INVALID_GEOMETRY_TYPE
INVALID_PARAMETER_PRECISION
INVALID_PARAMETER_FLATTENING
INVALID_PARAMETER_COMPRESSION_WEIGHT
INVALID_PARAMETER_SMOOTHNESS_WEIGHT
INVALID_PARAMETER_ACCURACY_WEIGHT
INVALID_PARAMETER_GENERALIZATION_TOLERANCE
INVALID_PARAMETER_SMOOTHNESS_FACTOR
INVALID_PARAMETER_SHARPNESS_ANGLE
INVALID_PARAMETER_NUMBER_OF_NEIGHBORS
INVALID_PARAMETER_DISPLACEMENTPERCENTAGE
INVALID_PARAMETER_WEIGHTING_POWER
INVALID_PARAMETER_DEGREE_OF_BASIS_POLYNOMIAL
INVALID_PARAMETER_SEGMENT_LENGTH
INVALID_PARAMETER_FILLET_RADIUS
Rejected Feature Handling: can be set to either terminate the translation or continue running when it encounters a rejected feature. This setting is available both as a default FME option and as a workspace parameter.
Parameters
|
Group By |
The default behavior is to use the entire set of input features as the group. This option allows you to select attributes that define which groups to form. Each set of features which have the same value for all of these attributes will be processed as an independent group. |
||||
|
Complete Groups
|
Select the point in processing at which groups are processed:
There are two typical reasons for using When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations. The second possible reason is potential performance gains. Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains). Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with When All Features Received may be the equivalent and simpler approach. Note Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
|
Algorithm |
Select an algorithm to apply. See How does it work? above for details. |
|
Generalization Tolerance |
Specify an appropriate tolerance value. See individual algorithms for specifics. |
|
Preserve Shared Boundaries |
Select a method for handling adjacent areas that have boundaries in common:
Note that overlapping areas may need pre-processing with an AreaOnAreaOverlayer or Snapper(Vertex Snapping) for expected results. |
|
Shared Boundaries Tolerance |
The minimum distance between boundaries in 2D before they are considered shared, in ground units. If the tolerance is Automatic, a tolerance will be automatically computed based on the location of the input geometries. |
|
Preserve Path Segments |
Select a method for handling features with path geometry:
|
|
Number of Neighbors |
See McMaster and McMaster Weighted Distance or Inflection Points. |
|
Displacement Percentage |
|
|
Weighting Power |
|
Fillet Radius |
See Fillet |
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
|
|
Feature Holding |
No |
| Dependencies | None |
| Aliases | LineGeneralizer AreaGeneralizer AreaSmoother LineSmoother |
| History |
FME Community
The FME Community has a wealth of FME knowledge with over 20,000 active members worldwide. Get help with FME, share knowledge, and connect with users globally.
Search for all results about the Generalizer on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.