Calculates statistics based on a designated attribute or set of attributes of the incoming features and adds the results as attributes.
Typical Uses
- Inspecting and analyzing features
- Calculating statistics for use in further operations
How does it work?
The StatisticsCalculator receives features and calculates selected statistics on them per attribute. Statistics can be calculated on specific groups of input features as specified by the Group By attribute option. The results are output on each feature out of the Complete port. A summary of the results is output out of the Summary port.
Available statistics include:
- Minimum
- Maximum
- Total Count
- Sum
- Mean
- Median
- Numeric Count
- Value Count
- Range
- Standard Deviation (Sample or Population)
- Mode
- Histogram
The following statistics may also be calculated cumulatively on attributes using advanced settings: min, max, range, mean, stdev, sum, total count, numeric count, and value count. When calculating cumulative statistics, the current results thus far are output on each feature out of the Cumulative port.
Statistics are stored as attributes, named <attribute>.<statisticname>, where <statisticname> will be one of the following: min, max, range, mean, stdev, stdev_p, sum, median, mode, total_count, numeric_count, value_count, histogram.
Histogram statistics are stored as list attributes that pair the attribute value and count for each unique value of the attribute and are named <attribute>.histogram{#}.value and <attribute>.histogram{#}.count where # is a zero-based index of the unique attribute values.
Input Data Handling
Invalid, <null>, and <missing> data are considered invalid and will be skipped when calculating statistics other than total count. If no valid values are processed when calculating a statistic the result will be <missing>. Trying to calculate standard deviation on only one value will also result in <missing>. Total count, numeric count, and value count will never be <missing>. NaN values are explicitly ignored when calculating Min, Max, Range, and Numeric Count.
For example, a calculated sum on all <missing> values will be <missing> rather than a potentially misleading and less informative 0. However, if only some values are <missing> or invalid the resulting sum will be the same as if those values were 0.
Example
The StatisticsCalculator transformer can generate statistics for groups of features rather than all features. This effectively adds the ability to create pivot tables in FME similar to pivot tables in Excel.
Note: The AttributePivoter transformer provides a simpler approach to generate some forms of pivot tables.
Source Table and Excel Pivot Table
Fictitious data generated in Excel was exported to a CSV file for use in Workbench. A simple pivot table was also created in Excel to show what we want to produce from FME; basically we want to summarize observed values based on region and potential.
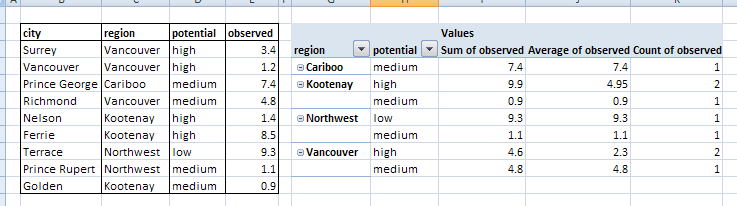
FME Pivot Table
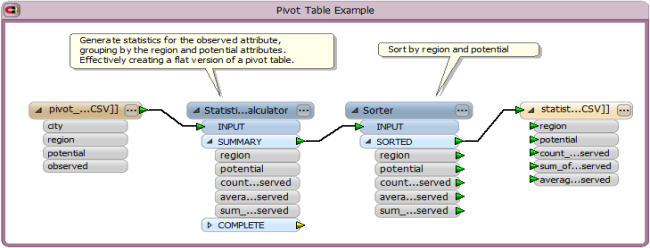
The workspace shown below uses the StatisticsCalculator transformer to create statistics for the observed attribute by first grouping features by region and potential. Then the new statistics features are sorted by region and potential, and output to a CSV file. The resulting CSV file has all of the same attributes/fields as the Excel pivot table.
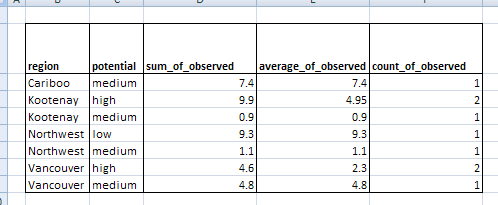
The table written by FME and viewed in Excel resembles the Excel pivot table:
You can also use the ChartGenerator transformer to chart the data.
Usage Notes
-
The StatisticsCalculator transformer has default suffixes and always prepends. Upgraded transformers will retain prepend settings when output attribute names were not prepended before upgrade as well as suffix names to maintain backwards compatibility and avoid disrupting existing workspaces.
Configuration
Input Ports
All features enter the transformer through the Input port.
Output Ports
A single new feature will be output containing the statistics attributes for each group. If features are not grouped, the latter will emit a single feature containing the statistics for the whole set of input features.
No summary features will be generated if no input features are provided.
All Input features will all be passed through this output port with all the statistics attributes for their group added onto them. Note that this will require all Input features to be stored until the end of translation, which can greatly increase the amount of memory and/or temporary disk storage usage.
All Input features will all be passed through this output port with all the statistics attributes to date for their group added onto them. The features pass through this port immediately, each having the statistics computed for the set of features from the first feature in the group through to the current feature. (Note that this differs from the “final” statistics output in the Complete group.)
Parameters
| Group By | If Group By attributes are chosen, statistics will be calculated independently within each group of features. This can be used to create a pivot-table-like analysis of values in a data stream. |
| Complete Groups |
When All Features Received: This is the default behavior. Processing will only occur in this transformer once all input is present. When Group Changes (Advanced): This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger processing on the currently accumulating group. This may improve overall speed (particularly with multiple, equally-sized groups), but could cause undesired behavior if input groups are not truly ordered. There are two typical reasons for using When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations. The second possible reason is potential performance gains. Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains). Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with When All Features Received may be the equivalent and simpler approach. Note: Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order. As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
| Calculation Method |
Use this setting to specify a method for evaluating values when calculating statistics. This choice will be applied to all data when it enters the transformer, determining whether values should be treated numerically or lexically. |
| Attribute | Select which attributes to include, one per line. | ||||||||||||||||||||||||||
| Statistics |
The following statistics may be calculated:
|
||||||||||||||||||||||||||
|
Select All |
This toggle works in conjunction with currently selected rows in the Statistics to Calculate table and will enable or disable all statistic type choices. |
||||||||||||||||||||||||||
|
Add Attributes... |
Provides a pick list of all currently available attributes to perform multiple attribute addition to the Statistics to Calculate table. |
Enable this section to calculate cumulative statistics and make the Cumulative output port visible. This table specifies which cumulative statistics to calculate for each attribute.
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters. There are a number of tools and shortcuts that can assist in constructing values, generally available from the drop-down context menu adjacent to the value field.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Dialog Options - Tables
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
FME Community
The FME Community is the place for demos, how-tos, articles, FAQs, and more. Get answers to your questions, learn from other users, and suggest, vote, and comment on new features.
Search for samples and information about this transformer on the FME Community.