Defining Alert Conditions
Alert conditions define the logic that triggers an alert.
Mouse-over for screenshot:
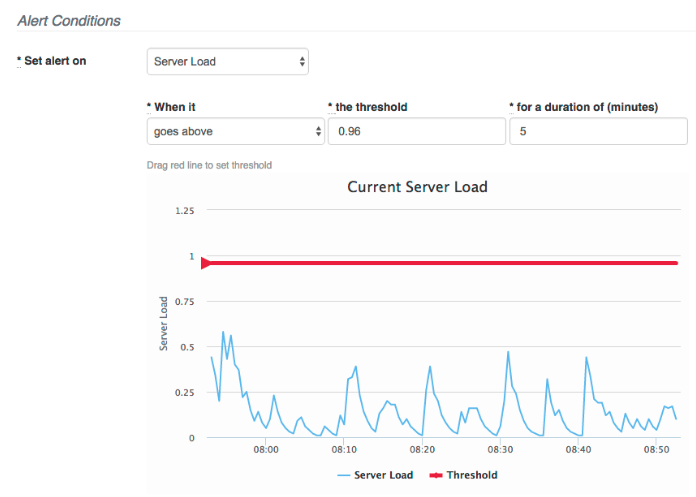
The alert condition reads like a sentence. In the example above, the condition is:
Set an alert on Server Load when the average goes above 0.4 for a duration of at least 5 minutes.
Condition to Measure (Set alert on)
Primary Disk Usage refers to the data storage you specified when you launched or resized the instance. The Primary disk contains the full FME Flow installation, including resources and the PostGIS database. For more information, see this Safe Software Blog post.
If the disk runs out of space completely, the server will crash. Usually, you want to trigger alerts when you are close to running out of storage. It is good practice to set two tiers of alerts:
- A low-priority alert that triggers when disk usage goes above 85%, associated with less aggressive messaging, such as e-mail.
- A high-priority alert when disk usage goes above 95%, and sends messages to notification services that people will see immediately.
Server load expresses how many processes are waiting in the queue to access the processor, and can be a very useful indicator of whether there is an issue with the server. If there are a lot of processes backing up, then the load increases.
- 0 means there is no wait for an incoming process.
- 1 means the CPU core is at capacity.
- Over 1 means there is a backup.
When configuring alerts for server load, keep in mind the following:
- The trigger value (threshold): If your load stays consistently above 0.7, you are nearing capacity, and you should consider investigating the server. If your load stays above 1, there is a problem or the server is underpowered. If your load stays above 5 the server is likely in serious trouble, and the instance is either hanging or unresponsive.
- Your instance type: The total number of CPUs equals approximately the maximum capacity. For example, the Enterprise instance type has 16 CPUs, so the load should not exceed 16.
- Duration: A higher duration results in fewer alerts triggered by small, but valid, spikes in traffic. As a starting point, we suggested a duration of approximately 30 minutes.
The number of FME Engines available to run on the instance depends on the instance type.
Usually, you want to trigger alerts when the instance shows zero engines ("falls below 1"), which means there is no capacity to process jobs. We recommend the default duration of five minutes.
Server response time is the internal response time of the web server that serves the FME Flow web application and REST API. A long response time indicates an instance that is underpowered because of high load, or an issue with the server (memory leak or runaway process) that has stolen resources.
Usually, you want to trigger alerts when response time goes above 2000 ms (2seconds). You may want to raise the duration from the default (5 minutes) to 10 minutes to avoid alerts triggered by a spike in traffic that slows the server down temporarily. Sustained response times over 3 seconds the mean the FME Flow Web User Interface and REST API are non-responsive. In this case, we recommend sending alerts to high-priority notification groups.
Server response time is an "internal" response time, referring to a request from the same machine, rather than over an external network. Because server response time is significantly lower than actual response time, any Internet connection issues may not trigger an alert.
The amount of memory currently in use on the instance depends on the instance type.
The primary components of FME Flow that cause fluctuations in memory in normal conditions are the FME Engines, which are used to run FME workspaces. The amount of memory used by an engine when running a job depends entirely on the workspace. Some workspaces will use lots of memory, while others almost none.
When an instance runs out of memory, FME Flow will slow or become unresponsive, FME processes may crash (beginning with the engine), and other unexpected behaviors may occur.
Temporary Disk Usage refers to the temporary data storage you specified when you launched or resized the instance. The temporary disk maps to the Temp Resources folder on FME Flow. It is erased when the instance is paused, and it is not backed up. Nevertheless, you may want to know when temporary disk storage reaches a certain threshold.
Condition Type (When it)
- Goes above: Alert fires if the incoming value exceeds the threshold.
- Falls below: Alert fires if the incoming value falls below the threshold.
Threshold value (the threshold)
The value of the condition to measure that determines when an alert fires.
Threshold (for a duration of)
The time window during which the trigger condition must be met for the average of measurements coming in. For example, if you only want to be notified if disk usage is over 95% for at least 10 minutes, set to 10. The maximum allowed value is 60 minutes.