FME Form: 2025.1
Dataset fanout writes a different dataset for each division of data. How this actually appears as output depends whether you are working with a file-based format or a folder-based format.
For an introduction to dataset and feature type fanout, see About Fanout.
Steps
- In the Workspace Navigator, double click on the Destination dataset of the writer you want to fanout.
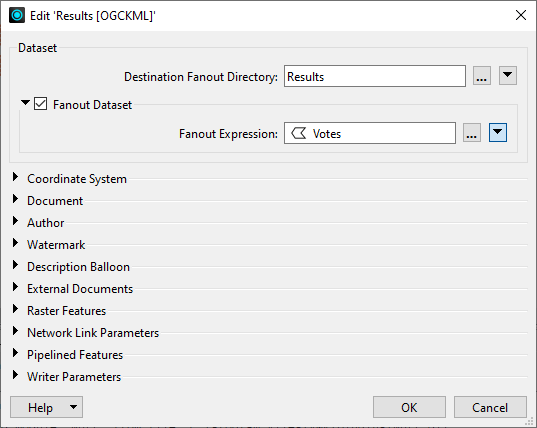
- In the Destination Fanout Directory field, specify a directory to hold the fanout datasets.
- Check Fanout Dataset and provide a Fanout Expression to indicate how you want to fanout the dataset.
- Click OK.
An Edit Dataset dialog opens.
Click the ellipsis  to use the Text Editor to assemble an expression of constants, parameters, and output attributes.
to use the Text Editor to assemble an expression of constants, parameters, and output attributes.
For File-Based Datasets, the expression should evaluate to the full filename of the output files, including any prefixes and file extensions (for example, internal\KML\@Value(PathName).gml or @Value(PathName).dwg).
For example,
you want to perform a dataset fanout in Google KML format, and three features
are output: two have Votes attribute equal to candidate, and one has Votes attribute equal to write_in. If Destination Fanout Directory is C:\ and Fanout Expression is Votes (or @Value(Votes) in the Text Editor), you will end up with datasets in two folders: c:\candidate\ and c:\write_in\. The output filenames will be based on the output feature types specified in the workspace.
Note If attribute values have the same name, but the filenames are different letter cases (upper-/lowercase letters), then, in a Windows environment, the
previously created file will be overwritten by a subsequent writer on a Windows
machine.
For example, say there are two input source filenames and the only difference between them is that one is lowercase (3s1w35.dgn) and one is uppercase (3S1W35.dgn). With dataset fanout, you will get two unique values. Because FME creates two different writers during the translation, the second writer will overwrite the file created by the first. This is because on Windows, filenames are case-preserving but also case-insensitive for various operations. To avoid this, add a StringCaseChanger transformer to the workspace to make sure the attribute names are consistent.
Combining Feature Type and Dataset Fanouts
You can combine Feature Type and Dataset Fanouts.
For example, if you are working with a folder-based format and you perform a feature type fanout on attribute A and a dataset fanout on attribute B, then you'll end up with multiple folders of files, with the filenames dependent on the values of attribute A.
Dataset Fanout and Temporary Disk Storage
Note that a Dataset Fanout can have a huge impact on temporary disk storage, since there is no guarantee that features arrive at the fanout in a single dataset group. Therefore, FME has to write all of the datasets to temporary storage then fan them out afterwards.
Feature Type Fanout has no similar issues, so you may have more success if your destination format is folder-based.