Each FME translation is usually run as a single process on your computer. This means that normally, FME sequentially processes each group of features specified in the Group By parameter. Versions of FME 2012+ can use multiple-core processors, which, on modern personal computers, allows multiple tasks to be performed in parallel. FME also uses hyper-threading, a technology used to make each physical core appear as two logical processors to the host operating system. By splitting the workload between cores/processors, FME performance can improve.
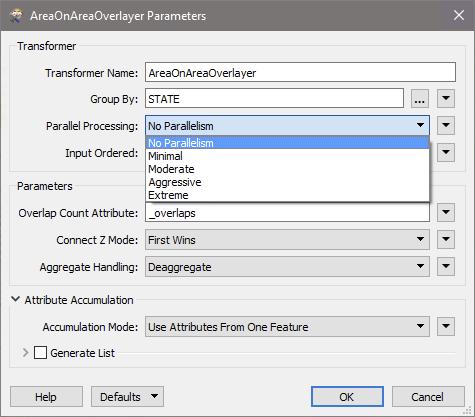
In transformers that support this feature, parallel processing lets you run a transformation as several simultaneous processes. The Group-By parameter allows you to assign features to processes. The Parallel Processing parameter allows you to define different levels of processing, from No Parallelism to Extreme.
In the example here, the Group By parameter is set to STATE based on the reader dataset. By setting the Parallel Processing level, FME can run each state as a separate, simultaneous process.
For example, on a quad-core machine, minimal parallelism will result in two simultaneous FME processes. Extreme parallelism on an 8-core machine would result in 16 simultaneous processes. You can experiment with this feature and view the information in the Windows Task Manager and the Workbench Log window. For more information, see Parallel Processing Level Parameter, below.
Note: FME License: There is a limit to the number of processes available for FME licenses: Base Edition: 4; Professional Edition: 8; All other editions: 16.
When parallel processing is enabled, FME processes groups of features in parallel by spawning a new fmeworker.exe instance for each group of features.

In the Workbench Log, information messages show license limit (if applicable), the request, process memory usage for each "worker", and identifying information about each -WORKER_KEY:
|
<DATE> 11:25:16| 2.0| 0.0|INFORM|The current FME license has limited the number of workers to `16' <DATE> 11:25:16| 2.0| 0.0|INFORM|AreaOnAreaOverlayer: The Parallel processing level of `MODERATE' has requested `8' workers <DATE> 11:25:23| 0.0| 0.0|INFORM|11> START - ProcessID: 6852, peak process memory usage: 26384 kB, current process memory usage: 26384 kB <DATE> 11:25:23| 0.0| 0.0|INFORM|11> FME Configuration: Command line arguments are `C:\apps\FME_2013\fmeworker' `C:\Users\<USER>\AppData\Local\Temp\childProcMap1353957917240_7552.fme' `LOG_STANDARDOUT' `YES' `-WORKER_CAPABILITY' `215L804U4L92U1L10U1L5U1' `-WORKER_KEY' `4120345835' |
Note: When FME spawns an additional process, it needs to send the input features to the new process and receive the output features from the process. This adds additional CPU overhead when compared to single-process mode.
To use parallel processing, the workflow should have several groups of features that can each be processed independently. Each group will become a separate (parallel) process. Some grouping techniques are discussed below.
The level of parallelism (how many processes can be executed at a single time) depends on the Parallel Processing parameter, which has five modes:
Depending on the operation performed, one mode can be more advantageous than another, and Aggressive or Extreme does not always provide the best performance: in some workspaces, parallel processing does not provide any advantage; in other workspaces, minimal or moderate levels of parallelism are the best choice (for example, surface-related transformers such as SurfaceModeller or TINGenerator usually work best with these options).
Parallel processing is incorporated into some transformers, and you can also expose its functionality through custom transformers.
To use Parallel Processing on a custom transformer, click the Transformer Parameters in the Navigator pane:
A custom transformer with parallel processing does not have to be limited to a single transformer within it: you can use multiple transformers.
For more information on using parallel processing with custom transformers, see The FME Evangelist.
Parallel processing can improve FME performance; but it can also degrade it or have very little effect. When using parallel processes, it is important that the processing (CPU) time for each group is anticipated to be significantly more than the overhead of launching a new process and sending the features back and forth between processes. If this is not the case, then enabling parallel processing will be slower than using no parallelism.
Trying a small subset of your data in multi-processing mode will help you determine whether there is an advantage to using it on an entire dataset.
Parallel processing is not recommended when you have many groups, each with a small number of features. Each group spawns an FME process and that takes time. For example, with 10,000 groups of 10 features, you might find it costs more performance to start and stop FME 10,000 times than you save in parallel processing. Conversely, 10 groups of 10,000 features might be more worthwhile.
Parallel processing only provides an advantage when data volumes are large enough: for smaller datasets, the overhead of running multiple processes can easily make the translation slower than a single process.
You need to ensure other system resources such as memory are adequate for the task. Firing up eight processes to do heavy polygon dissolving when you have eight cores is fine, but if you only have 2GB of memory then you may actually slow down a translation.
Parallel processing is extremely efficient when the task is being offloaded elsewhere. For example, if you have multiple requests to make via the HTTPCaller, it might be worth using parallel processing because the impact on system resources is small.
When the task involves writing to disk, spawning multiple processes will not speed up the task.