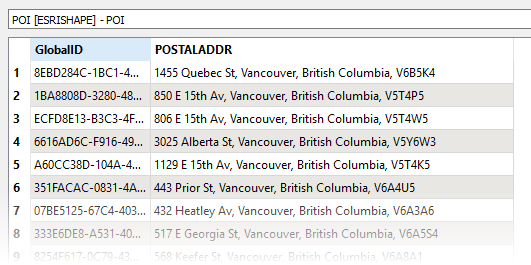
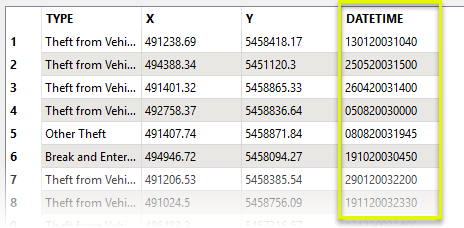
In this example, we have a dataset of food trees. For each location, there may be any number of individual trees, and the names of the varieties are stored in the FOOD_TREE_VARIETIES attribute. The names of the varieties are separated by semicolons - “;”.
We will split this attribute into a list attribute for further processing in the workspace.
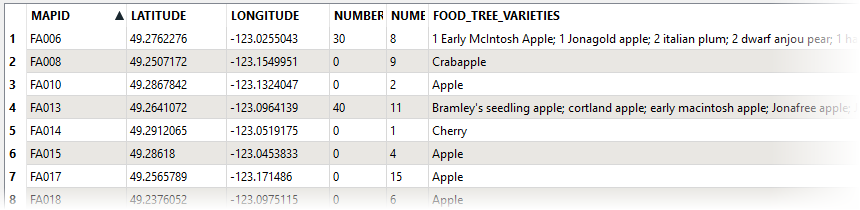
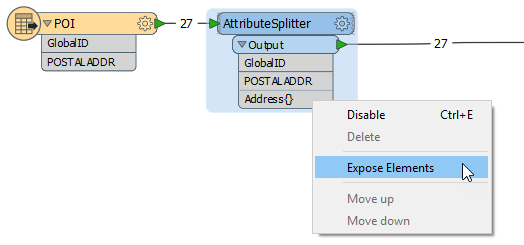
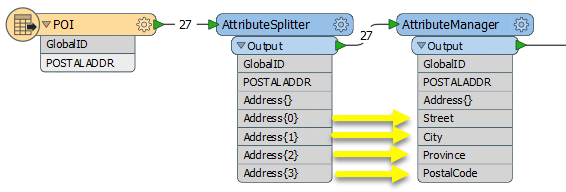
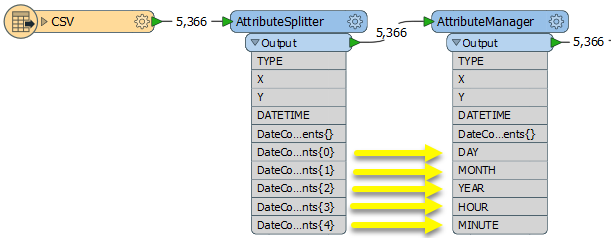
The Food Trees dataset is routed into an AttributeSplitter, where the new list attribute - Varieties{} - will be created.
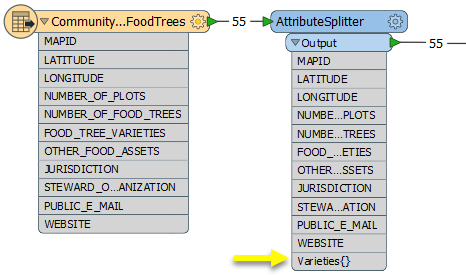
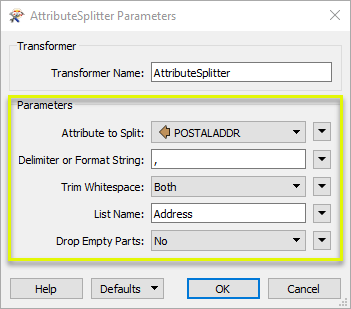
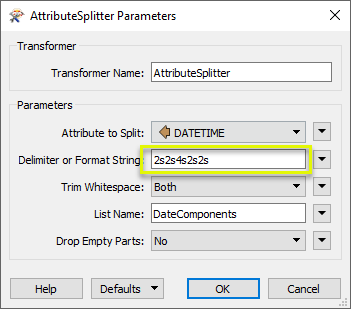
In the parameters dialog, we select the name of the attribute and define how the split should be done. Delimiter or Format String is set to ; (semicolon), any whitespace will be trimmed, any empty parts will be dropped, and the new list attribute is named Varieties.
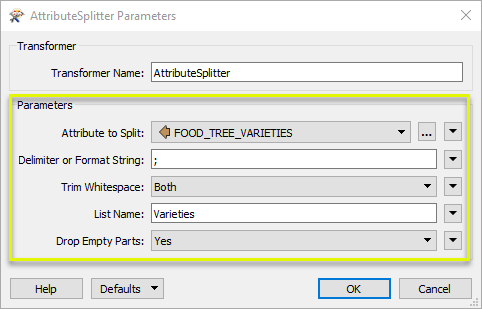
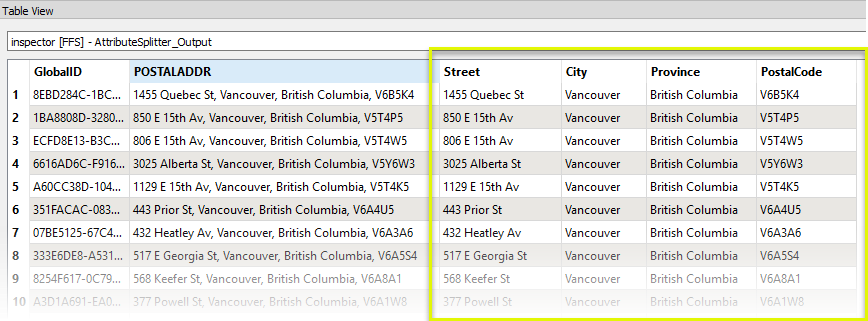
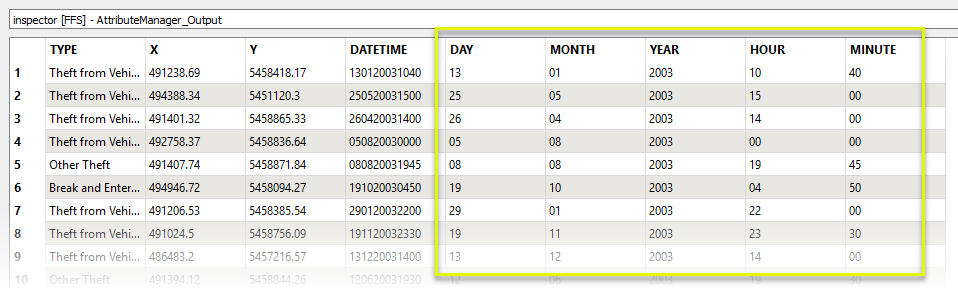
Viewing the results in the Data Inspector, the FOOD_TREE_VARIETIES attribute has been split into its component parts, and the parts have been added as individual elements to the new list attribute.
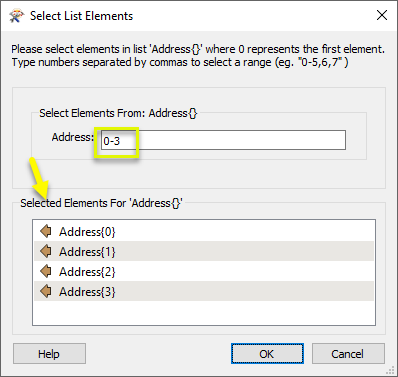
 beside the applicable parameter. For more information, see
beside the applicable parameter. For more information, see