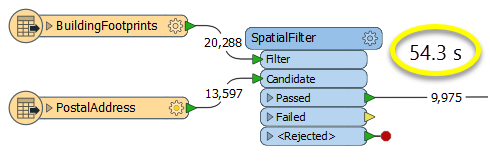
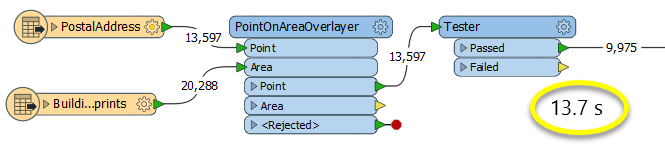
In this example, we perform an overlay of rapid transit stations points on rapid transit lines. The source data, as seen here, contains three individual transit routes, each one a single line feature.

The station points are close to the lines, but not right on them - generally within a meter.
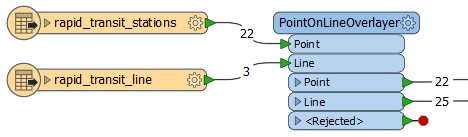
The stations are connected to the Point input port, and the routes are connected to the Line input port.
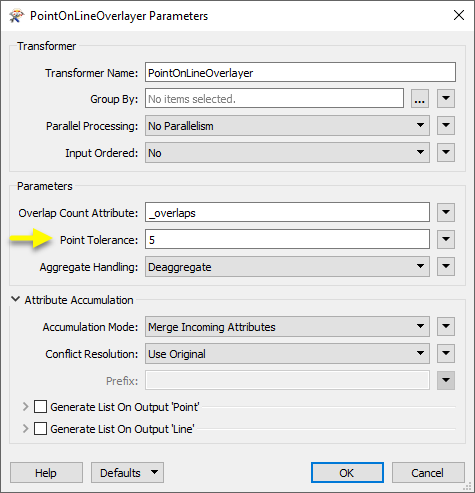
In the PointOnLineOverlayer parameters dialog, we enter a tolerance of “5” - meaning 5 meters, as these datasets are in a UTM projection, with ground units in meters. We also choose to merge attributes.
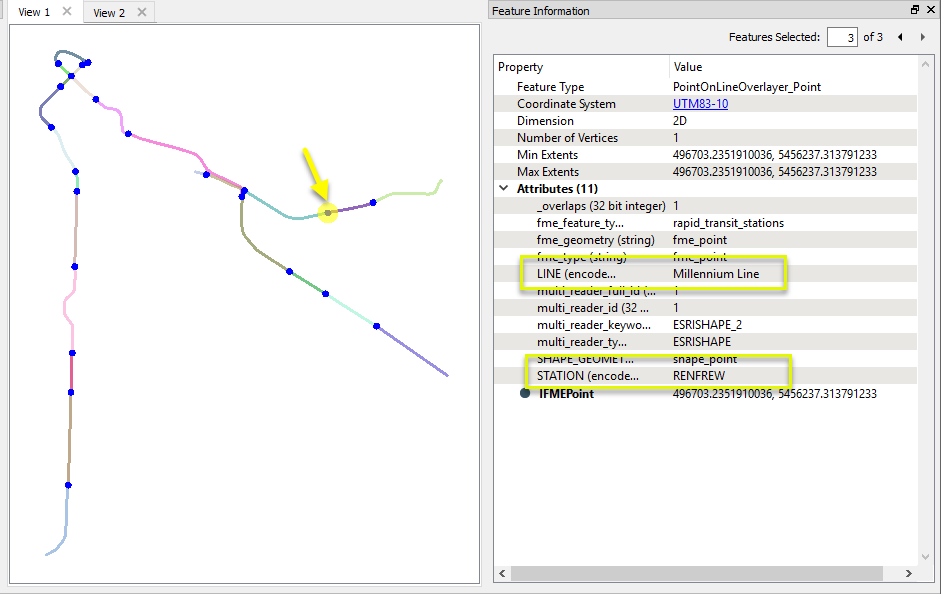
The transit lines are split where they encounter a station within the specified tolerance, as shown here by randomly coloring the output line features. Attributes are shared between the points and lines, as in these point attributes for Renfrew Station, which now has a new attribute indicating that it overlaid the Millennium Line.
Output Lines receive attributes from all of the points that the original unchopped line encountered - see Usage Notes for more detail.
 beside the applicable parameter. For more information, see
beside the applicable parameter. For more information, see