FME Transformers: 2026.1
Categories
Calculated Values
Related Transformers
NetworkFlowOrientor
NetworkTopologyCalculator
ShortestPathFinder
StreamOrderCalculator
Calculates the primary and secondary streams of multiple stream networks. The key to determining the priority is the shortest path algorithm using multiple iterations within a network graph.
This attribute defines, for each source junction of the network, a unique path (the shortest path) to reach the destination junction. All flow lines included in a path (from the sources to the destination) will have a stream priority attribute set to 1 (primary); all others are set to 2 (secondary).
Before using this transformer, you will need to specify the weights on the network lines in the source data by specifying the Forward Weight Attribute and optionally Reverse Weight Attribute if the network graph is non-oriented.
A weight is a property of a network line typically used to represent a cost for traversing across a network line. An example of a line weight is the length of the line. In a shortest path analysis, you would choose this weight if you wanted the resulting path to be of the shortest length. For line features, 2 weights can be used: one along the digitized direction of the line feature (the forward weight) and one against the digitized direction of the line feature (the reverse weight). The digitized direction of a line feature refers to the order of the vertices.
The goal is to flag the loops (cycles) in the network in order to highlight the primary network lines.
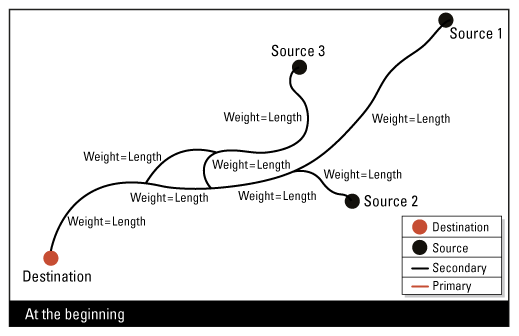
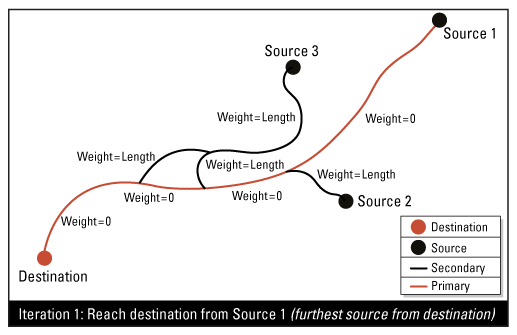
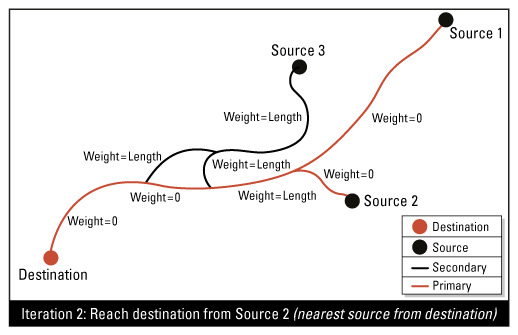
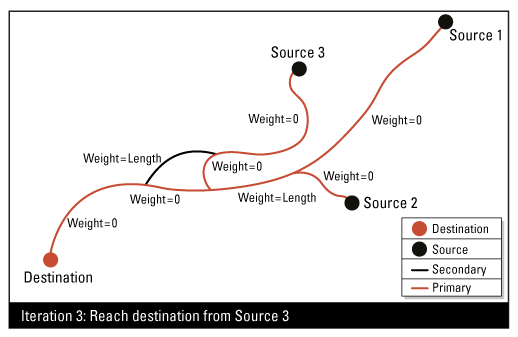
Expected Output
- Network lines with a stream priority attribute set to 1 (primary) or 2 (secondary). If it’s not possible to determine the priority (if there isn't a destination located on network graph) a stream priority attribute is set to -1. The network lines have also a Graph Identifier attribute. All network lines in a same graph will have the same value in this attribute.
- Unused destination (if the destination is not located on an end point of the network graph)
Examples
This transformer can be used on network linear flow lines. There are two ways to determine the stream priority attribute:
- To calculate the stream priority attribute for the oriented network lines: for these lines, the digitized direction represents a downstream flow direction.
- To calculate the stream priority attribute for the non-oriented network lines: for these lines, the digitized direction is not significant.
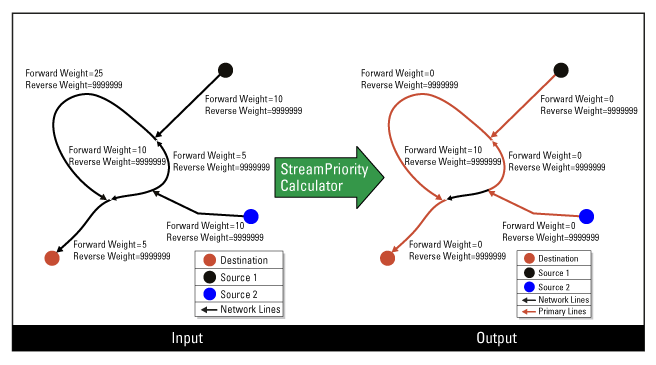
Calculating the Stream Priority for Oriented Network Lines
When the network lines are oriented, the shortest path should not go against the digitized direction. So initially the weight along the digitized direction (the forward weight) is the length, and the weight against the digitized direction (reverse weight) is a bigger value.
Note that the reverse weight is optional, and usually not required.
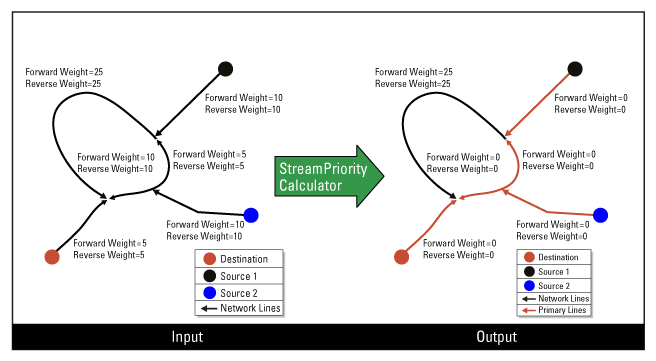
Calculating the Stream Priority for Non-Oriented Network Lines
When the network lines are not oriented, the digitized direction of network lines is not significant. So the weight along the digitized direction (forward weight) and the weight against the digitized direction (reverse weight) are the same. In this case, you can use the same attribute corresponding to the length for both weight parameters. In this way, the loops are removed for the primary network lines (stream priority=1) and you can apply other algorithm to modify the digitized direction. This is how you can make network lines primary (stream priority=1) where the digitized direction represents a downstream flow direction.
Configuration
Input Ports
Network lines with cycles (loops).
Destination nodes, located on an end point (leaf) of the network graph. All other end points on the network graph are considered sources.
Output Ports
Streams that are connected will be assigned the same network ID attribute.
Only one destination node is allowed per network. Any extra destination nodes found are output through the ExtraDestination port.
Destination nodes that are not found on any network are output through the Invalid port. All non-linear features are also output through the Invalid port.
Parameters
|
Group By |
The default behavior is to use the entire set of input features as the group. This option allows you to select attributes that define which groups to form. Each set of features that have the same value for all of these attributes will be processed as an independent group. |
||||
|
Complete Groups |
Select the point in processing at which groups are processed:
There are two typical reasons for using When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations. The second possible reason is potential performance gains. Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains). Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with When All Features Received may be the equivalent and simpler approach. Note Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
|
Dimension |
Select the type of coordinates to use when identifying topological connections:
|
|
Forward Weight Attribute |
An attribute name on the network lines that contains a weight along the digitized direction. This parameter is required to apply the shortest path algorithm. |
|
Reverse Weight Attribute |
An attribute name on the network lines that contains a weight against the digitized direction. This parameter is required to apply the shortest path algorithm if the digitized direction of network lines is significant. By example, the digitized direction can represent a downstream flow direction for a hydrographical network. If the digitized direction is not significant for a network graph, a user can provide the same attribute of the Forward Weight Attribute parameter. |
|
Network ID |
Streams that are connected will be assigned the same network ID in the Network ID Attribute. All streams will be assigned a stream priority value in the Stream Priority Attribute with either -1, 1 or 2. Streams that are not connected to the destination nodes will be assigned level priority value of -1. Meanwhile, primary or secondary streams will be assigned level priority value of 1 or 2 respectively. |
|
Stream Priority |
Name the attribute to contain the stream priority value (1 for primary or 2 for secondary) for output network lines. |
Editing Transformer Parameters
Transformer parameters can be set by directly entering values, using expressions, or referencing other elements in the workspace such as attribute values or user parameters. Various editors and context menus are available to assist. To see what is available, click  beside the applicable parameter.
beside the applicable parameter.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Table Tools
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
For more information, see Transformer Parameter Menu Options.
Reference
|
Processing Behavior |
|
|
Feature Holding |
Yes |
| Dependencies | None |
| Aliases | |
| History |
FME Online Resources
The FME Community and Support Center Knowledge Base have a wealth of information, including active forums with 35,000+ members and thousands of articles.
Search for all results about the StreamPriorityCalculator on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver, Open Government Licence - British Columbia, and/or Open Government Licence – Canada.