FME uses the Multi-Writer to create several different output datasets, possibly of different types and different coordinate systems, during one FME run.
This capability can be used to separate one dataset into many datasets based on a variety of partitioning schemes such as feature type, location, or the value of a feature attribute. For example, the roads from a Design file could be reprojected into UTM and output to a Shape Format file, while parcel boundaries from the same Design file could be reprojected into Orthographic and output to a MapInfo Native Format file.
Using the Multi-Writer in FME Workbench
To get multiple output datasets requires either a Dataset Fanout or a batch processing technique such as Batch Deploy.
For additional information, see Adding Multiple Writers in FME Workbench help.
How the Multi-Writer Works
During an FME run, the Multi-Writer accumulates features that are ready for output until the FME indicates that there are no more features to accumulate. The Multi-Writer then cycles through each writer, one at a time, and passes it the appropriate features. Based on the feature’s attributes, the Multi-Writer determines which writer it is destined for. When the data for the first writer is exhausted, the second writer is activated. This continues until the Multi-Writer runs out of features:
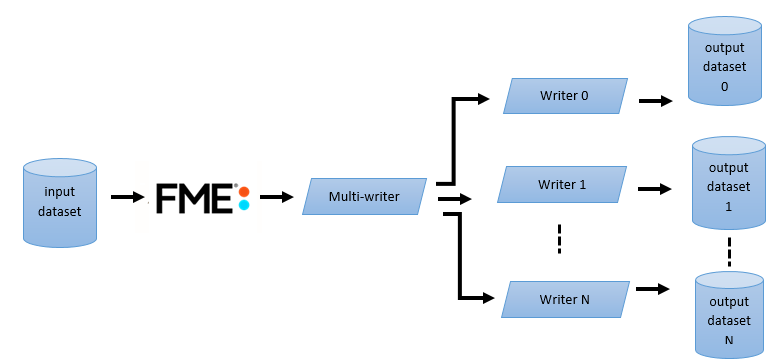
The Multi-Writer can be configured to operate in two different modes.
- The first mode allows the Multi-Writer to create datasets of different types during one FME run. In this mode, each individual writer available to the Multi-Writer is identified and configured in the workspace.
- The second mode allows the Multi-Writer to create multiple datasets of the same type during one FME run. In this mode, individual writers do not need to be identified or configured.
In both modes, the Multi-Writer uses the attributes of a feature to determine its destination dataset. In the mode where individual writers are specifically identified, the Multi-Writer will reject features that are destined for an unidentified writer. In the mode where individual writers are not specifically identified, the Multi-Writer will activate as many individual writers, all of the same type, as are identified by the features it receives from the FME.