|
To access feature type parameters, click the gear icon Tip To always display the editor in FME Workbench, you can select View > Windows > Parameter Editor.
General All feature types share similar General parameters, which may include Feature Type Name, Reader or Writer information, and Geometry. In most Writer Feature Type parameter dialogs, you can also control Dynamic Schema Definitions. Some database formats accept Table or Index Qualifier prefixes on the output table feature type. |
 on a feature type in the
on a feature type in the Table Settings: General
This parameter specifies how features will be written into the destination table. Supported feature operations are described below. Note that the described behavior can be dependent on the selected options, as well as the underlying table properties.
- More information about Feature Operations.
|
Option |
Description |
If the Row Does Not Exist |
If the Row Exists |
|
Insert |
The writer appends a new row to a table using input feature attributes. |
The writer creates a new row using input feature attributes. |
Not always applicable: if the table does not have a unique key or it has an automatically generated unique key, insertion is always possible. The database cannot violate its key constraints; therefore, errors can occur on row insertion. For example, if there is a unique key and a user specifies the value with the feature, and the feature already exists, then FME Workbench logs an error. This error might be in the form of a rejected feature, or the database may stop processing altogether. |
|
Update |
The writer updates existing row(s) in a table using input feature attributes. A selection method must be specified in the Row Selection group. |
The writer rejects the input feature or logs an error if it is unable to continue. |
The writer only changes values of the existing row(s) corresponding to the input feature that differ from the input feature. |
|
Upsert |
The writer appends a new row or updates an existing row(s) using input feature attributes and/or geometries. A selection method must be specified in the Row Selection group. |
The writer creates a new row using input feature attributes and/or geometries. |
The writer changes values of the existing row(s) corresponding to the input feature that differ from the input feature. It leaves other attributes untouched. |
|
Delete |
The writer deletes an existing row(s) in a table. A selection method must be specified in the Row Selection group. |
The writer rejects the input feature or logs an error if it is unable to continue. |
The writer deletes existing row(s) corresponding to the input feature. |
|
fme_db_ |
The feature operation will be determined by the attribute fme_db_operation on each input feature. A selection method must be specified in the Row Selection group. The value of fme_db_operation will be processed according to the steps below. Note The processing steps listed below depend on a format's available Feature Operation options.
Note about earlier FME versions: To use fme_db_operation, you must set Feature Operation to this option. In previous versions of FME, you could set fme_db_operation when the destination feature type was set to Insert, Update, Upsert, or Delete. Doing this now will cause feature rejection. |
The action depends on the operation; however, in general, if nothing is specified, the value is treated as an Insert. | The value is treated as an Insert. |
Controls how the feature type handles destination tables:
- Use Existing – Write to an existing table If the destination table does not exist, the translation will fail.
- Create If Needed – Create the destination table if it does not exist.
- Drop and Create – (This option is not available in all formats.) Drop the destination table if it exists, and then create it. The writer will drop and re-create the table before writing any features to it. Tables will be overwritten when the first input feature is processed. If no features are sent to a feature type, then the corresponding table will not be overwritten.
- Truncate Existing – (This option is not available in all formats.) If the destination table does not exist, the translation will fail. Otherwise, delete all rows from the existing table.
When updating or upserting features, users have a choice to update, or skip, their spatial column(s). Possible options are:
- Yes: The spatial column(s) specified by the user will be updated. IFMENulls will be written as null values and replace existing spatial values.
- No: No spatial columns will be updated.
|
Feature Operation Option |
Row Selection |
|---|---|
|
Insert |
Row Selection is ignored. |
|
Update, Upsert, Delete (Options may differ depending on a format's available Feature Operation options.) |
A Row Selection condition needs to be specified for selecting which rows to operate on. |
This parameter group offers two methods to construct the selection condition:
Match Columns
The columns specified in the corresponding column picker dialog will be used for matching destination rows. All matching rows will be selected for update, upsert, or delete. If any feature attributes corresponding to the specified match columns contain null or missing values, the feature will be rejected.
WHERE Clause
This parameter opens a WHERE Clause Builder. You can also type a WHERE clause inline, without launching the Builder. It is optional to start the clause with the word WHERE.
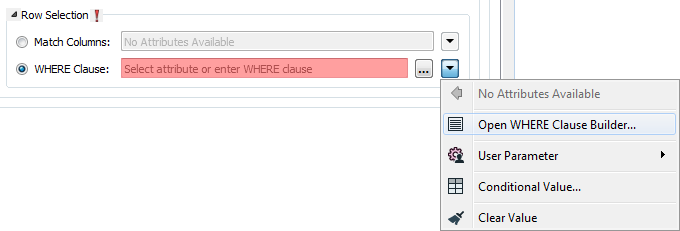
The WHERE Clause Builder makes it easy for users to reference feature attribute values, destination table columns, and invoke FME functions. The WHERE clause is first evaluated as an FME expression, before being passed onto the destination database.
If the WHERE clause is incorrect or if its evaluation results in failure, the translation will fail. Otherwise, if the WHERE clause passes FME evaluation but it is SQL invalid, the feature will be rejected or the translation will fail.
For advanced users, conditional FME expressions created through the Conditional Value editor can be used to create WHERE clauses.
Table Creation
This optional field determines whether or not the dataset contains z coordinates. Valid values are Yes, No, or Blank. The default is Blank which will take the value from the table parameter.
This optional field specifies whether or not the features will contain measures. Valid values are Yes, No, or Blank. The default is Blank which will take the value from the table parameter.
Origin and Scale
The coordinates of the X false origins for all feature classes and all feature datasets. This is used as an offset so that coordinate data is stored as positive integers, which allows a range from 0 to 2147483647 (so if the X origin is set below 0, then the maximum value will also drop, and vice versa). By default, the values for the false origins are set to 0. This is only used when creating new feature classes.
The coordinates of the Y false origins for all feature classes and all feature datasets. This is used as an offset so that coordinate data is stored as positive integers, which allows a range from 0 to 2147483647 (so if the Y origin is set below 0, then the maximum value will also drop, and vice versa). By default, the values for the false origins are set to 0. This is only used when creating new feature classes.
A scaling conversion factor from world units to integer system units for all feature classes and all feature datasets. This is used to specify the level of precision to keep when storing XY coordinates, since all coordinates are stored as integers.
The x,y scale is the inverse of the spatial reference's XY Resolution. The resolution is defined as the minimum unit in map units that separate unique x values and unique y values for feature coordinates.
The coordinates of the Z false origins for all feature classes and all feature datasets. This is used as an offset so that coordinate data is stored as positive integers, which allows a range from 0 to 2147483647 (so if the Z origin is set below 0, then the maximum value will also drop, and vice versa).
By default, the values for the false origins are set to 0.
A scaling conversion factor from world units to integer system units for all feature classes and all feature datasets. This parameter is used to specify the level of precision to keep when storing Z coordinates, since all coordinates are stored as integers.
Depending on the scale, it changes the precision of the coordinates stored. For example, if you have the coordinate (5.354, 566.35) and you set the Z Scale to 100, then the coordinate stored will be (5.35, 566.35).
The default value is 100.
The minimum measures value possible. This is used as an offset because measure data is stored as positive integers (0 to 2147483647) relative to the measures origin.
A scaling conversion factor from world units to integer system units for all feature classes.
Annotation
This optional field specifies what reference scale to use when creating an annotation feature class. The reference scale determines the scale at which the text’s size, on the screen, is the size indicated on each annotation feature. When the scale is larger in value than the reference scale, then the text appears smaller than that indicated on the annotation feature, and vice versa.
If no value is specified for this field, then FME uses first annotation feature for the annotation feature class. If the feature contains the attribute geodb_text_ref_scale then the value for the attribute is used as the reference scale. If the attribute doesn’t exist, then the default value for the attribute is used, which is 1.
Advanced
Specifies the name of the column containing object IDs for the current table or feature class. If the value conflicts with a user attribute, then the writer will change the value for this field (by appending a numeric suffix) and log a warning.
Specifies the alias for the object IDs column for the current table or feature class. The alias is used in ArcMap (and possibly in other ArcGIS products) when viewing data; the object ID column will be labeled by its alias.
Specifies the name of the column containing the shape data for features in the current feature class. This applies only to feature classes. If the value conflicts with a user attribute, then the writer will change the value for this field (by appending a numeric suffix) and log a warning.
Specifies the alias for the shape data column. This applies only to feature classes. When viewing data in ArcMap (and possibly in other ArcGIS products), the shape data column will be labeled by its alias. The default value is SHAPE.
Specifies the configuration keyword. See ArcGIS documentation for additional details.
Sets the global grid 1 size for the whole translation. For the Enterprise Geodatabase writer, the default is 1000. This directive is only used when creating new feature classes.
This optional field specifies the estimated average number of points per feature. It is used in the creation of the spatial index for the feature class.
If this configuration parameter is not specified, then a default value will be assigned to the feature class, depending on its geometry type. This parameter must be an integer.
|
Geometry Type |
Default Value (integer) |
|---|---|
|
point |
1 |
|
multipoint |
10 |
|
polyline |
20 |
|
polygon |
40 |