Merging Similar Datasets
If data sources reside in different locations, you can select them using the advanced browser.
You can add datasets of the same format and with the same schema (data model) to any source dataset you have already defined in your workspace. These datasets will be merged together when you run the translation. For formats that support coverages, you can also add folders and subfolders.
Double-click the dataset name in the Navigator.
In the Edit dialog, you can manually enter a path to a file, or multiple files (for example, *.tab).
|
Wildcard |
Description |
Example |
Matches |
Does not match |
|---|---|---|---|---|
|
? |
Matches any single character case-insensitively. |
?at | Cat, cat, Bat, bat |
at |
|
* |
Matches any sequence of zero or more characters case-insensitively. This match can occur in folder names, file names or file extensions, and can be used multiple times. |
Law* | Law, Laws, LawS, Lawyer | GrokLaw |
|
[abc] |
Matches a single character case sensitively | [CB]at | Cat, Bat |
cat or bat |
| [a-z] | Matches any single character in the range a-z inclusive and case-sensitively | [a-z]001 | a001 or b001 etc. | A001,a002 |
| [0-9] | Matches any single number in the range 0-9 inclusive. | Letter[4-5] | Letter4, Letter5 | Letters, Letter, Letter1 |
| [a-zA-Z] | Matches any single character in the range a-z or A-Z inclusive and case-sensitively. | test[a-zA-Z] | testAB, testab, testAz, or testZa | test |
|
{ab, cd, e} |
Matches any of the strings ab or cd or e. | Dir{One,Two} | DirOne, DirTwo |
DirThree, DirOneTwo |
| \\machine\dir | Matches an absolute UNC network path. | \\comp\temp |
Notes:
- Relative paths are respective to the dataset.
- Absolute or UNC paths are treated as such. Note that some expressions may not be interpreted correctly as absolute or UNC paths due to other characters in the pattern.
- Using forward slashes as separators provide the best results because forward slashes do not conflict with glob escape characters or UNC path names.
See also Common Path Filter Errors.
Additional Relative Path Examples
|
*.dgn |
Matches all files in the reader dataset folder that end with a .dgn extension. |
|
{data,archive}/*.dgn |
Matches all files in the reader dataset folder in either the data or archive subfolders that end with a .dgn extension. |
|
data/{d,p}*.shp |
Matches all files in the reader dataset folder that begin with a d or a p and that end with a .shp extension. The braces must be contained within a single path component, and cannot contain path separators. |
|
/data/92?034.dgn |
Matches all files in the data subfolder of the reader dataset folder that start with 92, have any single letter or number character, and end with 034.dgn. |
|
92[a-z]034.dgn |
Matches all files in the reader dataset folder that start with 92, then any single lowercase letter, and end with 034.dgn. |
|
data/**/*.shp |
Matches all files in the data subfolder of the reader dataset folder with a .shp file extension. |
Additional Absolute Path Examples
|
C:/data/*.dgn |
Matches all files in the c:/data folder that end with a .dgn extension. |
|
C:/{data,archive}/*.dgn |
Matches all files in the c:\data and c:\archive folders that end with a .dgn extension. |
|
Error |
Reason |
|---|---|
|
C:\data\*.dgn |
Single backslashes are interpreted as escape characters in the pattern. You can use forward slashes for path separators (C:/data/*.dgn), or escape the backslashes so they are treated as literals (C:\\data\\*.dgn). |
|
\\myfolder\*.csv |
If myfolder is a folder instead of a host, this will fail. Instead, use forward slashes for UNC paths and omit the leading separator for relative paths. For example: //myhost/*.csv myfolder/*.csv |
|
C[:]/*.txt |
Specifying the glob pattern syntax can sometimes conflict with the path interpretation. In this case, the optionality of the colon character prevents the recognition of the absolute path drive letter. You can try different combinations of the dataset and filter – these combinations may or may not succeed, depending on the conflict. |
| C:[data] |
Specifying the glob pattern syntax can sometimes conflict with special characters in the path. In this case, the directory contains square brackets [] which, by default, will be misinterpreted as a glob pattern. To ensure it is read correctly, remove the default glob pattern asterisk * and leave the Path Filter empty. This will disable glob interpretation and the path will be interpreted literally. |
You can also add multiple paths, separated by a comma.
Alternatively, click Select Multiple Folders/Files from the drop-down:
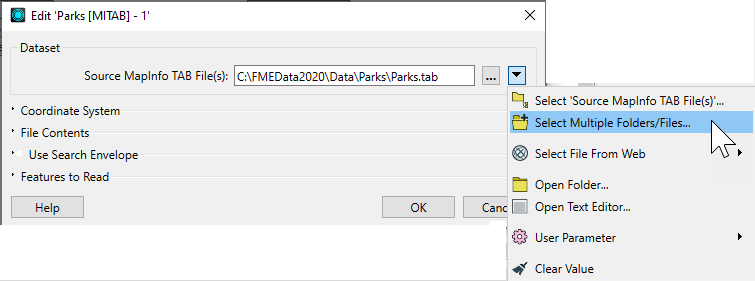
This opens the Select File dialog:
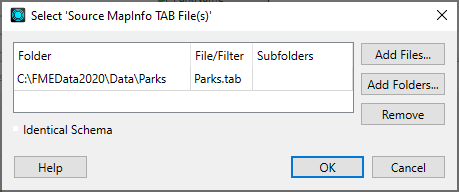
Add Files: Opens the file browser. You can select individual files, or Ctrl + click to select multiple files.
Add Folders: Opens the file browser so you can select entire folders to add to the reader. All files that are in the specified format in those folders will be included.
Remove: Removes the highlighted selection.
Subfolders: If there are subfolders below the initial dataset location, check the box to include them.
Identical Schema Check this box if you know that all the files have the same schema. This is a time-saving function: there will be no difference in the workspace results. If you know the files have the same schema, FME will not have to perform an initial scan of all the files to determine their schema. Instead, FME will take the first file as being representative of the data model.
Click OK to close the dialog, then OK to close Edit Parameter dialog and merge the selected files/folders with the original dataset. To see these results reflected in the Navigator view, float the cursor over the dataset name.