Produces a schema feature representing the feature type definition for each group of input data features.
Typical Uses
-
Generating a schema feature for dynamic writers
-
Generating schema features for comparison for schema validation and schema drift
-
Generating schemas after merging or manipulating datasets
How does it work?
The SchemaScanner receives features and determines their schema by scanning for attribute names and data types, based on the features' structure and attribute values.
It will scan either all features or a specified number of them, and can exclude certain attributes based on names, such as format-specific or internal FME attributes.
The resulting schema is output as a new schema feature, which has a specific form of list attribute and is output via the <Schema> port. It also receives a special attribute and value: fme_schema_handling = ‘schema_only’, which tells a dynamic writer to use that feature as a schema and then remove it from the output.
The original input features are passed out via the Output port, unchanged.
The output order of the schema features relative to the data (input features) can be controlled using the Output Schema Features Before Data. For use with dynamic writers, the schema features should be output first.
Attribute Generation
Schemas can be generated with unbounded or bounded attributes, according to the Numeric Type Format parameter:
-
Unbounded produces numeric types including int, uint, and real.
-
Bounded produces numeric types of fme_decimal(a,b) where a is the number of digits before the decimal, and b the number of digits after (precision). It is recommended to scan all features when using Bounded to ensure all existing attribute value lengths are considered.
String attributes are always bounded. SchemaScanner does not recognize date/time data types.
It does not maintain the original order of attributes.
Excluding Attributes
SchemaScanner processes all attributes on incoming features, including fme and format attributes. It is possible to ignore attributes using the Ignore Attributes Containing parameter.
Enter a regular expression, and matching attributes will be ignored.
For example, if the source data is CSV, you could use the regular expression ^fme_|^multi_|^csv_ to ignore any attributes starting with fme_, multi_, or csv_.
Schema Features
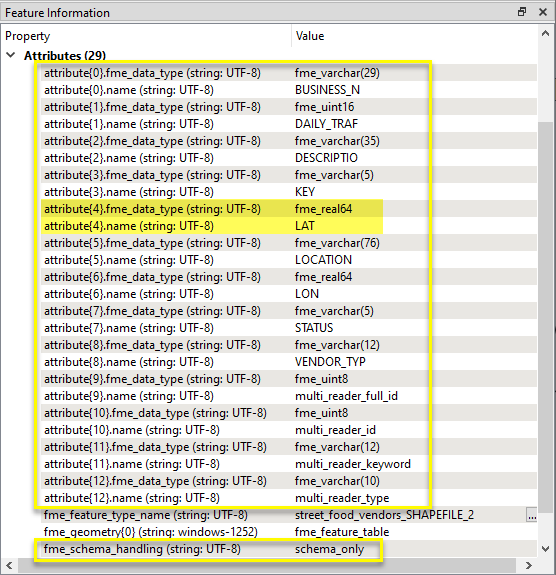
Schema features can be used to store or pass along schema structures - to dynamic writers, for example. The schema is stored in a list attribute named attribute, as shown here.
Each attribute has a name and an fme_data_type - note the attribute LAT has a corresponding data type of fme_real64.
Data types are FME internal data types.
Usage Notes
- Schema features may also be generated manually, or by using the FeatureReader's schema options. Two readers also generate schemas - the Schema (Any Format) reader and the Schema (From Table) reader.
- When using the SchemaScanner with a dynamic writer, the Output Schema Features Before Data parameter should be set to Yes, so that the schema arrives at the writer prior to the data features.
Configuration
Input Ports
This transformer accepts any feature.
Output Ports
All data features that were input are output here. The original order of the features may change if Group Processing is enabled.
One or more Schema Features - depending on whether Group Processing is enabled. Each schema feature has a list attribute in the form:
attribute{}.name
attribute{}.fme_data_type
One element for every attribute in the input data features.
The transformer adds a special attribute and value:
fme_schema_handling = ‘schema_only’
Parameters
| Group By |
If Group By attributes are selected, features with the same values in the Group By attributes are grouped together, and one schema per group will be produced. |
| Group By Mode |
Process At End (Blocking): This is the default behavior. Processing will only occur in this transformer once all input is present. Process When Group Changes (Advanced): This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger processing on the currently accumulating group. This may improve overall speed (particularly with multiple, equally-sized groups), but could cause undesired behavior if input groups are not truly ordered. There are two typical reasons for using Process When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations. The second possible reason is potential performance gains. Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains). Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with Process At End (Blocking) may be the equivalent and simpler approach. Note: Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order. As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains. |
| Output Schema Feature Before Data |
Select an ordering option for the schema features:
|
| Ignore Attributes Containing | Enter a regular expression. Attributes with matching names will be excluded from the schema. |
| Ignore Attributes is Case Sensitive | If Yes, the Ignore Attributes Containing regular expression matching will be case-sensitive. |
| Numeric Type Format |
Select the type of numeric value handling to be used in the schema:
|
|
Target Number of Features to Scan |
Specify the number of features to scan to determine the dataset schema. If blank, all features are scanned. If this number is greater than the number of features received, all features are scanned. For very large datasets, setting this parameter may improve performance. The default is blank - scan all features. |
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Defining Values
There are several ways to define a value for use in a Transformer. The simplest is to simply type in a value or string, which can include functions of various types such as attribute references, math and string functions, and workspace parameters. There are a number of tools and shortcuts that can assist in constructing values, generally available from the drop-down context menu adjacent to the value field.
Using the Text Editor
The Text Editor provides a convenient way to construct text strings (including regular expressions) from various data sources, such as attributes, parameters, and constants, where the result is used directly inside a parameter.
Using the Arithmetic Editor
The Arithmetic Editor provides a convenient way to construct math expressions from various data sources, such as attributes, parameters, and feature functions, where the result is used directly inside a parameter.
Conditional Values
Set values depending on one or more test conditions that either pass or fail.
Parameter Condition Definition Dialog
Content
Expressions and strings can include a number of functions, characters, parameters, and more.
When setting values - whether entered directly in a parameter or constructed using one of the editors - strings and expressions containing String, Math, Date/Time or FME Feature Functions will have those functions evaluated. Therefore, the names of these functions (in the form @<function_name>) should not be used as literal string values.
| These functions manipulate and format strings. | |
|
Special Characters |
A set of control characters is available in the Text Editor. |
| Math functions are available in both editors. | |
| Date/Time Functions | Date and time functions are available in the Text Editor. |
| These operators are available in the Arithmetic Editor. | |
| These return primarily feature-specific values. | |
| FME and workspace-specific parameters may be used. | |
| Creating and Modifying User Parameters | Create your own editable parameters. |
Dialog Options - Tables
Transformers with table-style parameters have additional tools for populating and manipulating values.
|
Row Reordering
|
Enabled once you have clicked on a row item. Choices include:
|
|
Cut, Copy, and Paste
|
Enabled once you have clicked on a row item. Choices include:
Cut, copy, and paste may be used within a transformer, or between transformers. |
|
Filter
|
Start typing a string, and the matrix will only display rows matching those characters. Searches all columns. This only affects the display of attributes within the transformer - it does not alter which attributes are output. |
|
Import
|
Import populates the table with a set of new attributes read from a dataset. Specific application varies between transformers. |
|
Reset/Refresh
|
Generally resets the table to its initial state, and may provide additional options to remove invalid entries. Behavior varies between transformers. |




Note: Not all tools are available in all transformers.
Reference
|
Processing Behavior |
|
|
Feature Holding |
If Output Schema Features Before Data is Yes then the transformer will block all the incoming data features. This is usually required if you are using the schema feature with a dynamic writer. Target Number of Features to Scan will also block the data features - up to the number of features selected (or all features, if left blank). |
| Dependencies | None |
| Aliases | |
| History |
FME Community
The FME Community is the place for demos, how-tos, articles, FAQs, and more. Get answers to your questions, learn from other users, and suggest, vote, and comment on new features.
Search for all results about the SchemaScanner on the FME Community.
Examples may contain information licensed under the Open Government Licence – Vancouver and/or the Open Government Licence – Canada.