|
About Database Connections |
|---|
|
Database formats include a Database Connection parameter that defines and stores authentication information. For general information about sharing database connections, please see Using Database Connections. Note that Database Connection parameters differ slightly, depending on context and/or database format. |
|
Connection From the Connection parameter in a database format, you can do one of the following:
|
Connection Parameters
Note: The source and destination dataset must be set to the database name.
This specifies the machine running the PostgreSQL ORDBMS as either an IP address or host name. The database must have proper permissions and be set up to accept TCP/IP connections if connecting from a remote machine.
When connecting remotely, this specifies the TCP/IP port on which to connect to the ORDBMS service. The default port is 5432.
Specify the name of the PostgreSQL database. The database must exist in the ORDBMS.
Note: In most cases, the Database field should be left with blank values, and the Dataset should contain the name of the PostgreSQL database.
Username and Password
Enter the username and password to access the service.
This parameter specifies the priority to be used for a secure SSL TCP/IP connection with the server. There are six modes:
- Disable: Try only a non-SSL connection.
- Allow: First try a non-SSL connection; if that fails, try an SSL connection.
- Prefer: (default) First try an SSL connection; if that fails, try a non-SSL connection.
- Require: Try only an SSL connection. If a root CA file is present, verify the certificate in the same way as if the Verify-CA option was selected.
- Verify-CA: Try only an SSL connection, and verify that the server certificate is issued by a trusted certificate authority (CA).
- Verify-Full: Try only an SSL connection, and verify that the server certificate is issued by a trusted CA and that the requested server host name matches that in the certificate.
Note: If you are having trouble connecting to the database, ensure you can connect to the database with the host, port, database, username, and password using psql. See PostgreSQL documentation for proper security and connection information, and for the usage of the psql utility.
Schemas for Tables
Schemas are used to organize tables. This parameter provides the list of viewable schemas.
If this parameter is left blank, the Tables dialog will only show choices from the search path for the current user. Selecting specific schemas here will cause tables from those schemas to be shown instead.
This parameter also specifies the schemas to fetch candidate tables when merging feature types. If it is not set, candidate tables are fetched based on the search path for the current user.
Constraints
After you have specified the database connection, click the Browse button (...) to select tables for import. A connection window appears while the system retrieves the tables from the database.
Once the Select Tables dialog appears, you can select one or more tables. Click OK to dismiss the window and add the selected table name(s) to the Tables parameter.
Note: If the list in the PostgreSQL Reader Parameters box does not display your table, try typing the name with the schema prefix (for example, public.mytable). If this works, then your search path for schemas may not be set to the desired values.
WHERE Clause
This parameter is used to constrain the row selection in tables chosen in the Tables parameter (for example, NUMLANES=2, LENGTH > 2000).
To construct a WHERE clause, click the browse button to open the editor. (You can also type a WHERE clause directly in the parameter field.)
If the WHERE clause SQL is invalid, the translation will fail.
Use this parameter to expose Format Attributes in Workbench when you create a workspace:
- In a dynamic scenario, it means these attributes can be passed to the output dataset at runtime.
- In a non-dynamic scenario, this parameter allows you to expose additional attributes on multiple feature types. Click the browse button to view the available format attributes (which are different for each format) for the reader.
Advanced
Number Of Records To Fetch At A Time
The number of rows that are retrieved at one time into local memory from the data source. For example, if the value is set to 10000, the reader reads 10,000 rows into local memory, and processes features from this memory buffer. After the reading the last row, the reader retrieves the next 10,000 rows from the data source.
Note: If this parameter is incorrectly set, it will cause significantly degraded performance. The optimum value depends primarily on the characteristics of individual records and the transport between the database and the client machine. It is less affected by the quantity of rows that are to be retrieved. The optimal value is the default value set for the format, and these values vary widely (for example, 1 for PostGIS Raster; 10 for Microsoft SQL Server; 10000 for PostGIS and Redshift).
SQL to Run Before Read
This parameter allows for the execution of SQL statements before opening a table for reading. For example, it may be necessary to create a temporary view before attempting to read from it.
For detailed information about SQL functions, click the corresponding menu item in the SQL to Run editor help![]()
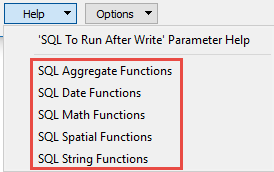 .
.
Available menu options depend on the format.
Multiple SQL commands can be delimited by a character specified using the FME_SQL_DELIMITER directive, embedded at the beginning of the SQL block. The single character following this directive will be used to split the SQL block into SQL statements, which will then be sent to the database for execution. Note: Include a space before the character.
For example:
FME_SQL_DELIMITER ; DELETE FROM instructors ; DELETE FROM people WHERE LastName='Doe' AND FirstName='John'
Multiple delimiters are not allowed and the delimiter character will be stripped before being sent to the database.
Any errors occurring during the execution of these SQL statements will normally terminate the reader or writer (depending on where the SQL statement is executed) with an error. If the specified statement is preceded by a hyphen (“-”), such errors are ignored.
SQL To Run After Read
This parameter allows for the execution of SQL statements after a set of tables has been read. For example, it may be necessary to clean up a temporary view after creating it.
For detailed information about SQL functions, click the corresponding menu item in the SQL to Run editor help![]() .
.
Available menu options depend on the format.
Multiple SQL commands can be delimited by a character specified using the FME_SQL_DELIMITER directive, embedded at the beginning of the SQL block. The single character following this directive will be used to split the SQL block into SQL statements, which will then be sent to the database for execution. Note: Include a space before the character.
For example:
FME_SQL_DELIMITER ; DELETE FROM instructors ; DELETE FROM people WHERE LastName='Doe' AND FirstName='John'
Multiple delimiters are not allowed and the delimiter character will be stripped before being sent to the database.
Any errors occurring during the execution of these SQL statements will normally terminate the reader or writer (depending on where the SQL statement is executed) with an error. If the specified statement is preceded by a hyphen (“-”), such errors are ignored.