To access feature type parameters, click the gear icon  on a feature type in the workspace to open the Feature Type Parameter Editor. To always display the editor in Workbench, you can select View > Windows > Parameter Editor.
on a feature type in the workspace to open the Feature Type Parameter Editor. To always display the editor in Workbench, you can select View > Windows > Parameter Editor.
General
All feature types share similar General parameters, which may include the Feature Type Name, Reader or Writer Name, and Geometry.
In most Writer Feature Type parameter dialogs, you can also control Dynamic Schema Definitions. Some database formats accept a Table Qualifier prefix on the output table feature type.
See Editing Writer Feature Types for more information.
These parameters apply only to a selected feature type, not to the entire writer.
Tip: If a feature type parameter listed here conflicts with a writer-level parameter, then the writer parameter will be ignored and this feature type parameter will be used.
Table Settings: General
This parameter lets the user specify how features will be written into the destination table. Supported feature operations are:
- Insert: Append rows onto the destination table using attributes on features.
- Update: Update existing table columns using attributes on features. A selection method must be specified in the Row Selection group.
- Delete: Delete existing table rows. A selection method must be specified in the Row Selection group.
- fme_db_operation: The feature operation will be determined by the attribute fme_db_operation on each input feature. A selection method must be specified in the Row Selection group. The value of fme_db_operation will be processed as follows:
- If the value is null, empty, or missing, it will be treated as Insert.
- The value will next be matched to Insert, Update, and Delete, case insensitively.
- If there is no match, the feature will be rejected.
- If there is a match, the matched feature operation will be performed on the feature.
Tip: The fme_db_operation attribute will now cause feature rejection when Feature Operation is set to Insert, Update, or Delete. This behavior differs from previous versions of FME.
More information on Feature Operations.
Controls how the feature type handles destination tables or lists. These options are available:
- Use Existing: Write to an existing table or list. If the destination table/list does not exist, the translation will fail.
- Create If Needed: Create destination table/list if it does not exist.
- Drop and Create: Drop destination table/list if it exists, and then create it. The writer will drop and re-create the table before writing any features to it. Tables will be overwritten when the first input feature is processed. If no features are sent to a feature type, then the corresponding table will not be overwritten.
- Truncate Existing: (This option is not available for all formats.) If destination table/list does not exist, the translation will fail. Otherwise, delete all rows from existing table or list.
Row Selection
When inserting into a table, Row Selection is ignored. When updating and deleting from a table (if applicable, based on a format's available Feature Operation options), a condition needs to be specified for selecting which rows to operate on. This parameter group offers two methods to construct the selection condition:
The columns specified in the corresponding column picker dialog will be used for matching destination rows. All matching rows will be selected for update or delete. If any feature attributes corresponding to the specified match columns contain null or missing values, the feature will be rejected.
This parameter opens a WHERE Clause Builder. You can also type a WHERE clause inline, without launching the Builder. It is optional to start the clause with the word WHERE.
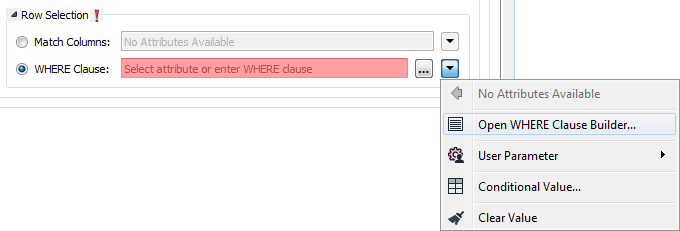
The WHERE Clause Builder makes it easy for users to reference feature attribute values, destination table columns, and invoke FME functions. The WHERE clause is first evaluated as an FME expression, before being passed onto the destination database.
If the WHERE clause is incorrect or if its evaluation results in failure, the translation will fail. Otherwise, if the WHERE clause passes FME evaluation but it is SQL invalid, the feature will be rejected or the translation will fail.
For advanced users, conditional FME expressions created through the Conditional Value editor can be used to create WHERE clauses.
Tip: You can set the WHERE Clause to an attribute. This supports workspace migration and existing workflows involving fme_where. (Direct support for fme_where has been deprecated.) To advanced users who are accustomed to using fme_where, if Feature Operation is set to Update, Delete, or fme_db_operation, an fme_where attribute that conflicts with Match Columns or WHERE Clause will result in feature rejection.
Table Creation Parameters
Specifies additional parameters (for example, table allocation characteristics) to be appended to the Oracle CREATE TABLE query used to create the output table. For example, to specify a tablespace, a STORAGE clause, and a comment for a table, the following clause could be appended:
TABLESPACE myTableSpace
STORAGE (INITIAL 50K);
COMMENT ON TABLE myTable IS ‘My new table’;
Table Settings: Advanced
Indicates which columns' values come from sequences. The syntax for this parameter’s value is of the form:
column1:seqname1;column2:seqname2
Where "columnN" is the name of the column whose value is provided by the sequence, and "seqnameN" is the name of the sequence in the Oracle database.
As a concrete example, the value of this parameter might be:
id:mySchema.test_sequence
Where id is also specified under the User Attributes tab. mySchema.test_sequence refers to a sequence named test_sequence in the schema mySchema.
If ":seqnameN" is not given, the column's value will be provided by a sequence with the same name as the column. Sequence names are case-sensitive. The sequences will be created if they do not already exist, in which case a message will be written to the log file.
Specifies a custom SQL query to process features. This parameter is usually used for INSERT, UPDATE, and DELETE operations that require custom SQL logic, such as exception handling. The values in the query can be bound by embedding :attrName in the query, where attrName is the name of the FME feature’s attribute. For example:
INSERT INTO "TEST_TABLE" ("ID") VALUES (:KEY)
In this example, the attribute named KEY will be taken from each feature written into the table column named “ID”. The attributes bound in the query must be listed in the User Attributes tab. The User Attribute types should align with the column types in the table schema.
As another example, consider this UPDATE query:
UPDATE "TEST_TABLE" SET "VALUE"=:MYVALUE WHERE "ID"=:MYID
In this example, the attribute named MYID from each feature is matched against the column “ID”. Matching rows will have their “VALUE” column updated by the value of the MYVALUE attribute on the feature. Once again, MYVALUE and MYID need to be specified in the User Attributes tab.
Tip: As part of a workflow using "best practices", you should ensure that the User Attribute name and its corresponding attribute name in the bound statement are identical, inclusive of letter case. If the pairing is identical except for letter case, the User Attribute name will prevail unless an attribute with that name does not exist on the feature; in this case, the bound attribute name will prevail. If the bound attribute name also does not exist on the feature, the value of the nonexistent attribute should default to null.
Because of this override behavior, when there are multiple attributes on the feature with identical names except for letter case, and you want to bind an attribute whose name is not all uppercase, you may need to uncheck the Upper Case Column Names parameter in the writer parameter box when you add the writer.
Note: It is not necessary (or recommended) to wrap bound attribute names in quotes: in testing, :myID behaved the same as the quoted :”myID”. If you do wrap bound attribute names in quotes, then you must do this for every bound attribute name.