Connects input linear (arcs and lines) features in the order they enter, forming path features.
If the end point of one input segment does not match the following segment's start point, geometry will be added to connect them in the following way. If the first segment is a line, then a point will be appended to it to extend it to the following segment's start point. If the first segment is an arc and the following segment is a line, then a point will be added to the beginning of the line to extend it to the first segment's end point. Otherwise, if both segments are arcs, then a two-point line will be inserted between these segments in the resulting path.
Usage Notes
- To create the desired path, it may be necessary to use a Sorter to order the data correctly before it enters this transformer.
- It is possible to create self-intersecting paths with this transformer, which will not be rejected.
Parameters
Transformer
The default behavior is to use the entire set of input features as the group. This option allows you to select attributes that define which groups to form – each set of features that have the same value for all of these attributes will be processed as an independent group.
The feature being created is output whenever a Group By value changes. When this happens, the feature with the differing attribute is not added to the current output feature; instead, it begins the next feature to be output.
If consecutive input segments are lines, they will not be combined into a single line in the output path; they will remain as separate segments. Also, if only one segment is input for a set of Group By values, the output will still be a path (containing that single segment).
Process At End (Blocking): This is the default behavior. Processing will only occur in this transformer once all input is present.
Process When Group Changes (Advanced): This transformer will process input groups in order. Changes of the value of the Group By parameter on the input stream will trigger processing on the currently accumulating group. This may improve overall speed (particularly with multiple, equally-sized groups), but could cause undesired behavior if input groups are not truly ordered.
There are two typical reasons for using Process When Group Changes (Advanced) . The first is incoming data that is intended to be processed in groups (and is already so ordered). In this case, the structure dictates Group By usage - not performance considerations.
The second possible reason is potential performance gains.
Performance gains are most likely when the data is already sorted (or read using a SQL ORDER BY statement) since less work is required of FME. If the data needs ordering, it can be sorted in the workspace (though the added processing overhead may negate any gains).
Sorting becomes more difficult according to the number of data streams. Multiple streams of data could be almost impossible to sort into the correct order, since all features matching a Group By value need to arrive before any features (of any feature type or dataset) belonging to the next group. In this case, using Group By with Process At End (Blocking) may be the equivalent and simpler approach.
Note: Multiple feature types and features from multiple datasets will not generally naturally occur in the correct order.
As with many scenarios, testing different approaches in your workspace with your data is the only definitive way to identify performance gains.
Parameters
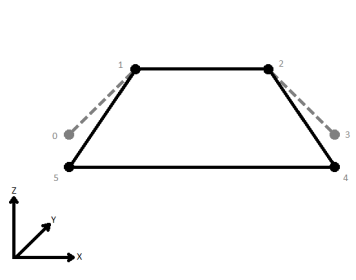
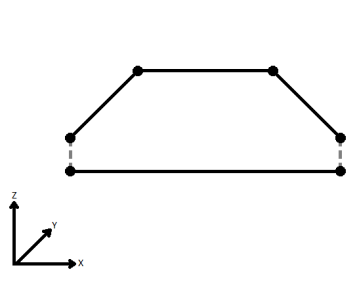
When viewed in 2D (ignoring Z), a path (which may define the border of a polygon) may appear to be closed as shown in the left figure below. This same path, when viewed in 3D, may appear to be open as shown in the right figure below.
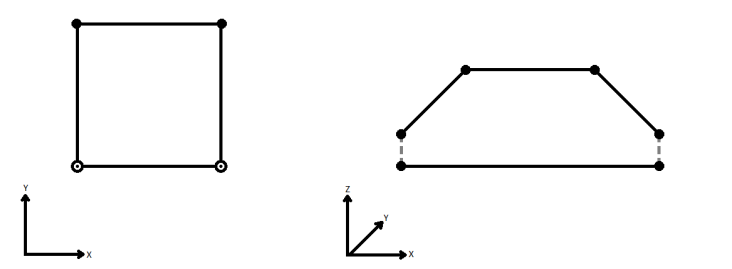
To specify how (and if) paths should be closed in 3D, select one of the listed modes.
| Mode | Description | Example |
|---|---|---|
| Extend | The Curve is extended so that all vertices are left at their original location. |
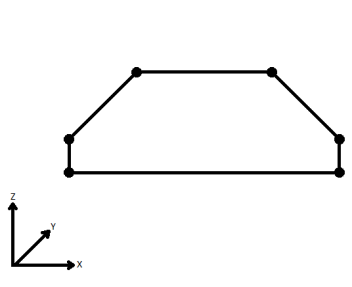
|
| Average | Subsequent vertices that are not connected, but share an x and a y value are combined into one vertex, whose Z value is the average of the original two. |
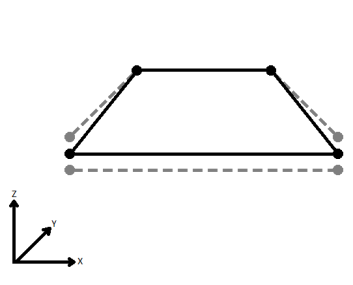
|
| First Wins | Subsequent vertices that are not connected, but share an x and a y value are combined into one vertex, whose Z value is taken from the first encountered vertex. |
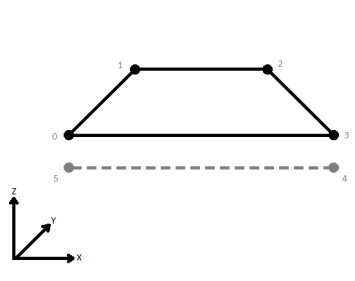
|
| Last Wins | Subsequent vertices that are not connected, but share an x and a y value are combined into one vertex, whose Z value is taken from the last encountered vertex. |
|
| Ignore | Z values are ignored. No change is made to the way the nodes are connected. |
|
Attribute Accumulation
Generate List
Enter a List Name to be created on each output feature, containing attributes of each feature that was connected when creating the output path.
This parameter can also be used to preserve attributes from input features.
Note: List attributes are not accessible from the output schema in Workbench unless they are first processed using a transformer that operates on them, such as ListExploder or ListConcatenator. Alternatively, AttributeExposer can be used.
All Attributes: Every attribute from all input features that created an output feature will be added to the list specified in List Name.
Selected Attributes: Only the attributes specified in the Selected Attributes parameter will be added to the list specified in List Name.
The attributes to be added to the list when Add To List is Selected Attributes.
Editing Transformer Parameters
Using a set of menu options, transformer parameters can be assigned by referencing other elements in the workspace. More advanced functions, such as an advanced editor and an arithmetic editor, are also available in some transformers. To access a menu of these options, click  beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
beside the applicable parameter. For more information, see Transformer Parameter Menu Options.
Transformer Categories
Search FME Community
Search for samples and information about this transformer on the FME Community.