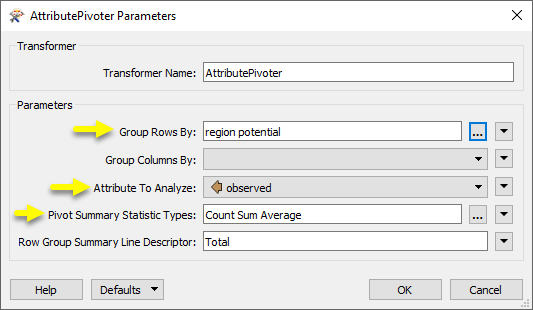
Group Rows By and (optionally) Group Columns By define a logical nesting of row groups.
For each such logically nested group, the AttributePivoter computes summary statistics, which it emits as table rows through the Summary port. The value for the most specific row grouping attribute for the summary row is given a value of “<attrName> <description>”, where <attrName> is the name of the row grouping attribute, and <description> is the value given to the “Row Group Summary Line Description” parameter.
For example, if grouping by an attribute called “Region_RSS”, the summary row over all regions would have a value of “Region_RSS Total” for the “Region_RSS” attribute, assuming the row group summary line descriptor is left with the default value of “Total”.
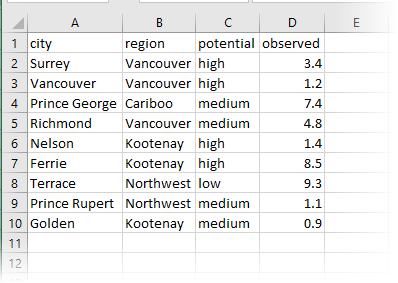
Input features are grouped by “grouping attributes”, and statistics are computed on the specified analyzed attribute in each group. There are two kinds of grouping attributes which work together to define these groups:
- Row Grouping Attributes: The user specifies an ordered set of attributes that divide the statistics into rows. There is a single row of result data for each unique set of values for the specified set of row grouping attributes.
- Column Grouping Attribute: The user can optionally specify a single attribute to define columns in the resulting rows. If specified, each unique value of the column grouping attribute contributes a column of statistical data to the result, for each statistic being computed. Additionally, if there is more than one unique value for the column, a summary column will be generated for each statistic.
If no column grouping attribute is selected, each row will contain a single computed result for each selected output statistic.
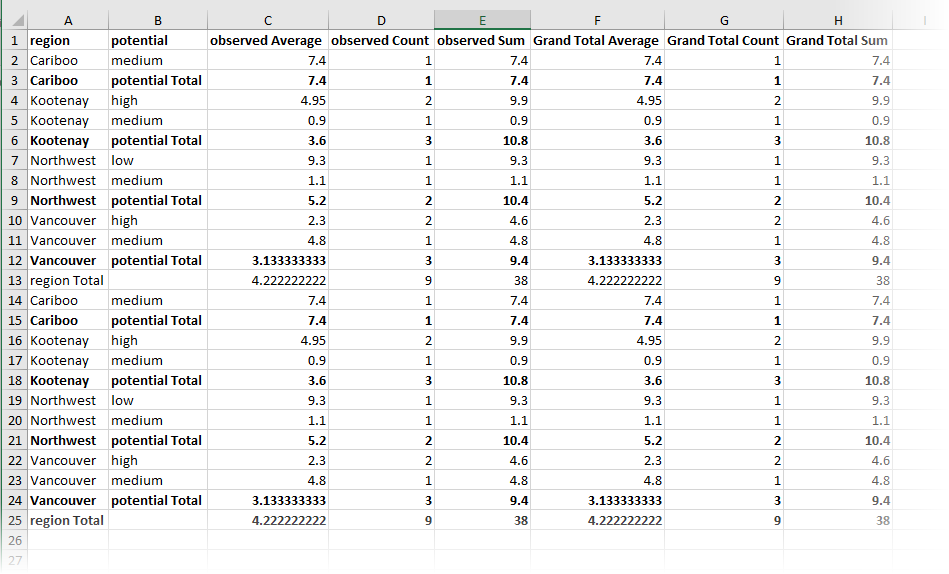
Because the row grouping attributes are ordered, they effect a logical nesting of groups. At the lowest level, a complete set of unique values is represented as a single row of the result. One level up is the logical grouping consisting of the set of rows where all row grouping attributes are unique except for the last one specified. This logical nesting carries up to the first specified row grouping attributes.
A row resulting from a complete set of unique data values is known as a “data row”. There is an additional “summary row” generated for each logically nested grouping, which summarizes the data for the data rows contained in the grouping.
The sequence of resulting rows form a table with the following attributes:
- All of the row grouping attributes, whose combined values specify the actual group
- For each pivot summary type, an attribute with the corresponding statistic, computed over all features in the row group.
- If there was more than a single column group defined, each of the attributes in (2.) will be repeated for all column groups, along with a summary value (i.e. a “grand total”) computed over the attribute values over all column groups. The method for computing the summary value depends on the statistic it is representing:
- Count and Sum statistics are summarized with the sum of the computed statistics for the row group.
- Average statistics are summarized with the average of all values in the row group.
- Min values are summarized by the minimum of all occurrences of the analyzed attribute for the group.
- Max values are summarized by the maximum of all occurrences of the analyzed attribute for the group.
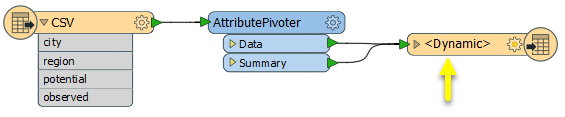
The first data feature and first summary feature emitted will contain additional attributes containing the schema information needed to write the data out by a feature type configured for dynamic writing.
 beside the applicable parameter. For more information, see
beside the applicable parameter. For more information, see