The Schema (Any Format) reader acts as a wrapper for the true reader which will be used to retrieve the schema from a specially formulated table in a given dataset.
The Schema (Any Format) reader takes a file or multiple files, folder, URL, or database name as the input dataset. If the format that is ultimately targeted requires an input folder, the Schema (Any Format) reader will turn the input filename into a folder by removing the file name part of the path.
Because the format it will read from can be, and is by default, published, workspace authors who want to set up specific dataflows for a particular format can use the ParameterFetcher transformer to retrieve the name of the format that actually is being read to, and then potentially route features to other transformers using this value.
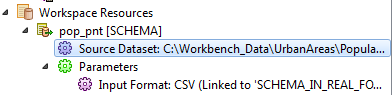
The Schema (Any Format) Schema reader reads the schema using the underlying reader, whose name is given by the Input Format workspace Navigator parameter.
Reading Formats that Contain Additional Parameters
The reader parameters for Schema (Any Format) are usually set by selecting a Format and Dataset. However, if you select a format like CSV or SQL Server, there are additional parameters that can control how the reader behaves. To expose a format's parameters in the Navigator pane, you will also have to add that format to the workspace as a resource.
From the Workbench menu bar, select Reader > Add Reader as Resource:
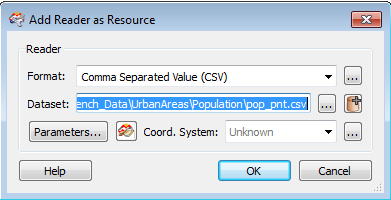
Any parameters you set here are also used by the Schema (Any Format) reader. However, the Source Dataset parameter on the Schema (Any Format) reader overrides this reader resource. For example, if you connect to a database, the Dataset is the database name. You will need to set this in the reader resource to make the database connection, but you also need to set it in the Schema (Any Format) Source Dataset parameter.